





Prévue dans le cadre de la loi santé votée il y a quelques mois, l’ouverture des données de santé va permettre d’étudier les maladies, les évolutions, les traitements.
La centralisation a parfois du bon. Avec près de 1,2 milliard de feuilles de soin (désormais sous format électronique sauf quand les médecins font de la résistance comme ce fut le cas des spécialistes en raison de la généralisation du tiers-payant), 500 millions d’actes médicaux et 11 millions d’hospitalisations, l’Assurance maladie gère l’une des plus grandes bases de données du monde. Et quand on observe les sommes dépensées par IBM pour acquérir de telles bases, on comprend la richesse que peuvent apporter de telles données.
Cette base de données baptisée Sniiram (Système national d’information inter-régimes de l’Assurance maladie) est désormais ouvertes aux chercheurs, institutions spécialisés, startups pour mener des études de pharmacovigilance, évaluer l’efficacité des soins, développer des applications, lancer des expérimentations, définir des politiques. Bref, c’est tout un univers qui est en train d’être défriché.
Créée en 1999 par la loi de financement de la sécurité sociale, les données sont récupérées et stockées pour poursuivre 4 objectifs:
– L’amélioration de la qualité des soins, en permettant par exemple l’évaluation des comportements de soin ;
– Une meilleure gestion de l’Assurance Maladie, grâce à l’évaluation précise des dépenses des régimes d’assurance maladie ;
– Une meilleure gestion des politiques de santé due notamment à une analyse possible des parcours de soin des patients ;
– La transmission aux professionnels de santé des informations pertinentes sur leur activité.
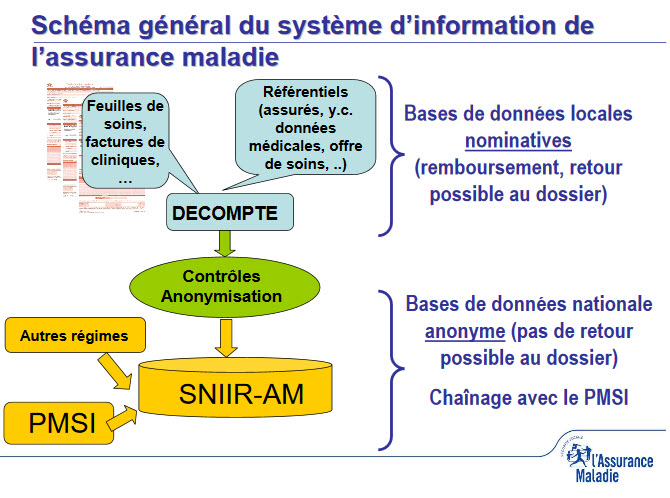
Le principal exploitant de la base Sniiram est l’Assurance maladie avec des champs d’action très large. On peut citer comme exemple, l’étude réalisée en 2013 avec l’Agence nationale de sécurité des médicaments (ANSM) concernait le risque thromboembolique des pilules de 3ème génération. Au-delà des études à caractère strictement médical, la Cnamts surveille l’évolution des dépenses et est capables de détecter des anomalies qui révèlent des anomalies.
Si cette base de données n’est aujourd’hui accessible qu’aux régimes d’assurance maladies, aux services ministériels, aux agences sanitaires et aux organismes publics de recherche, à l’exclusion de tout organisme poursuivant un but lucratif, La loi de santé promulguée en janvier dernier à permis d’en élargir l’accès. Dans les grandes lignes, elle prévoit les deux axes suivant :
– Open data : Les données agrégées et anonymisées ne contenant ni le nom des patients, ni leur adresse ou leur numéro de sécurité sociale seront accessibles à tous, gratuitement et sans restriction. La réutilisation de ces données sera autorisée si elle n’a « ni pour objet, ni pour effet, d’identifier les personnes concernées ».
– Données personnelles : Les données rendant l’identification possible pourront être utilisées sur autorisations de la CNIL et de l’INDS à des fins de recherche ou d’étude pour l’accomplissement de missions poursuivant un motif d’intérêt public uniquement, ce qui exclue une utilisation à des fins commerciales. L’accès sera donc restreint, encadré et payant par redevance.
Des jeux de données ont déjà été publiés sur la plate-forme sur la plate-forme du gouvernement. A partir de la base de données centrale qui représente un volume d’environ 1000 To ont été créés une quinzaine de datamarts thématiques, un EGB (un échantillon des bénéficiaires), une base de données individuelle des bénéficiaires (DCIR). Cette base ne peut être exploitée sans traitement préalable. La Cnamts a fait appel au Centre de mathématiques appliquées (CMAP), un laboratoire qui travaille en étroite liaison avec le Département d’Enseignement-Recherche en Mathématiques Appliquées de l’Ecole Polytechnique. Le CMAP utilise des algorithmes non supervisés permettant de détecter des signaux faibles ou anomalies en pharmaco-épidémiologie, l’identification de facteurs utiles à l’analyse des parcours de soins, la lutte contre les abus et la fraude…
L’École polytechnique a ouvert, en partenariat avec Télécom ParisTech, le Master « Mathématiques pour la sciences des masses de données » à la rentrée 2014. Le lancement de la formation « Data Scientist Starter Program » a complété cette offre en se destinant aux professionnels en activité. En octobre 2014, une Chaire « Data Scientist » a été créée, en partenariat avec Keyrus, Orange et Thalès.
Evidemment, la mise à disposition de ces données n’est pas causer quelques inquiétudes sur l’exploitation qui pourrait en être faite, en particulier par les compagnies d’assurance, avec des possibilités de débordement et d’atteinte à la vie privée et de divulgation du secret médical. Sans oublier les problèmes de cybersécurité et de trafic s potentiels. « Les données de santé qui contiennent des numéros de sécurité sociale et des adresses valent environ 20 fois plus qu’un numéro de carte de crédit sur le marché noir car les cybercriminels peuvent exploiter ces informations pour ouvrir plusieurs comptes frauduleux, explique Joël Mollo, directeur Europe du Sud de Skyhigh Networks. Les données relatives à des malades en phase terminale valent encore plus car malheureusement, il est peu probable que le patient ou sa famille détectent la fraude rapidement. Prenons l’exemple d’un employé d’hôpital qui vend ce type d’informations. Dans de nombreux cas, une organisation de santé n’a aucun moyen de détecter un comportement inapproprié des utilisateurs, qu’il soit intentionnel ou non. Comme la plupart des organisations se préoccupent principalement de surveiller les profils haut placés (cadres dirigeants, comptes à privilèges, etc.), elles sous-estiment encore beaucoup les menaces internes. »

 puis
puis