
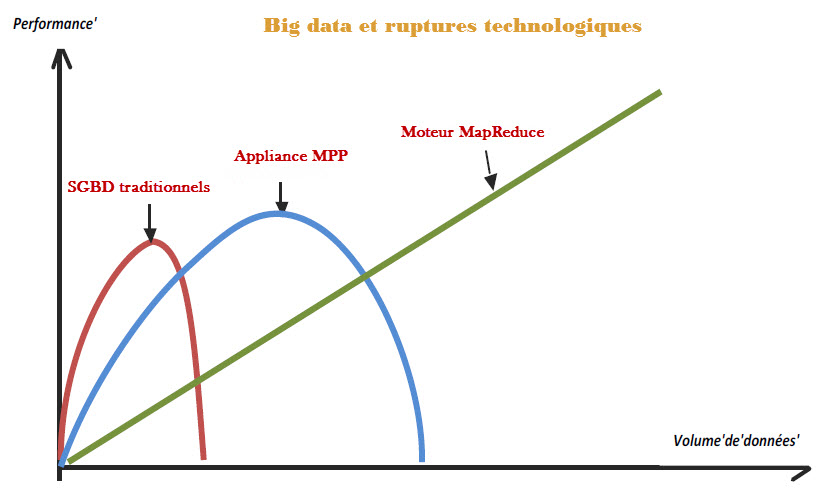
Le big data est une véritable révolution dans la mesure où il permet de faire des choses qu’on ne faisait pas avant parce qu’elles coûtaient trop cher.
Les technologies big data constituent une rupture avec les systèmes de BI traditionnels. Elles ne permettent pas de faire mieux, plus rapidement, elles permettent de lancer des projets auparavant impossibles à mettre en œuvre avec les technologies traditionnelles. Evidemment, il est difficile de « mettre à la poubelle » un système BI traditionnel (matériel + logiciel + services) dont on vient de s’équiper et qui à coûter fort cher. « Mais tôt ou tard, il faudra sans doute s’y résoudre » considère Romain Chaumais, directeur de développement d’Ysance, une société de conseil spécialisé dans le numérique qui prône une généralisation de l’utilisation des technologies Big data basées principalement sur hadoop. C’est en effet une approche de rupture et d’applications du big data à tous les problèmes posés aux métiers que suggère Ysance. « Pour gérer des volumes de plusieurs dizaines voire centaines de Téraoctets, les bases de données relationnelles traditionnelles sont inadaptées, poursuit Romain Chaumais. Les projets de Big Data nécessitent d’utiliser de nouvelles solutions techniques comme MapReduce et des bases massivement parallèles ».
 Les bénéfices des technologies hadoop sont multiples et peuvent énumérées comme suit :
Les bénéfices des technologies hadoop sont multiples et peuvent énumérées comme suit :
– Gestion des données structurées, peu structurées et non structurées : or il se trouve que les systèmes d’aujourd’hui génèrent de plus en plus de données non structurées pour lesquels les systèmes de BI traditionnels ne sont pas adaptés ;
– Pas de modèle de données à priori : c’est là aussi un des avantages des technologies hadoop qui par nature sont très flexibles ;
– Massivement Scale-Out (Gestion du temps contraint) : les technlogies hadoop sont assez largement linéaires. Ainsi, mettre 100 serveurs pour résoudre un problème permettra d’aller 100 fois plus vite. Ce qui justifie l’utilisation de solutions de type cloud en raison de l’élasticité qu’il offre ;
– De plus en plus compatible avec des usages temps réel (Flume, Hbase, Impala) : alors que les technologies hadoop était au début orienté batch, des solutions orientés temps réel permettent d’analyser les données au fil de l’eau ;
– Intégrée et compatible avec l’écosystème BI traditionnel ;
Les projets peuvent être classés en trois grandes catégories, chacune utilisant jusqu’ici ses propres outils :
– Une BI exploratoire qui se caractérise par des sources de données très volumineuses, peu ou pas structurées, collectées et/ou traitées au fil de l’eau ;
– Une BI correspondant à des sources de données volumineuses stables, maitrisées et industrialisées ;
– Et une BI départementale qui analyse des données peu volumineuses, métiers, locales, évolutives et hors DSI
Le cabinet Ysance propose donc une « extension des technologies Big Data aux problématiques décisionnels afin de disposer d’une plateforme de données unifiée, souple et scalable et de choisir Les Big Data comme socle unique de la BI (Voir aussi l’article de ce jour : Entre data et big data). La mise en perspective Big data vs BI ne semble donc pas jouer en faveur de cette dernière. Les éditeurs subissent aujourd’hui une grande pression pour être à la hauteur des attentes des entreprises. D’autant que le Big data, du fait de son écosystème Open Source (Hadoop) et Cloud, coûte beaucoup moins cher pour un nombre exponentiel de données et une moindre contrainte de traitement.
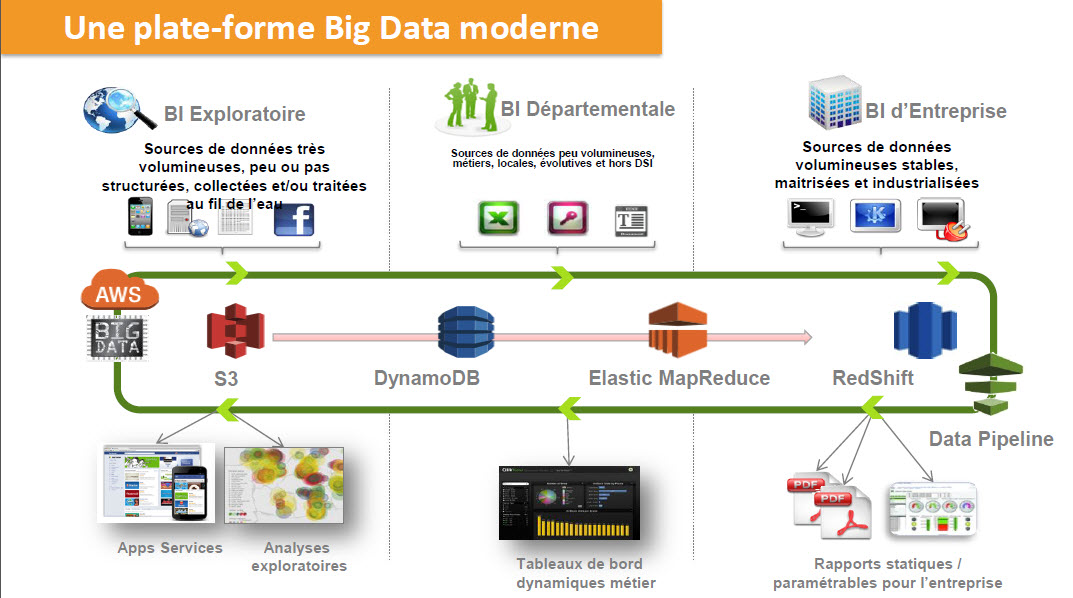
Ainsi Les caractéristiques du Big data font qu’il s’associe particulièrement bien avec des solutions de type cloud tels que ceux proposés par AWS et dont les deux services de base sont EMR
(Elastic Map Reduce) et Redshift qui est présenté par AWS comme une sorte de Data Warehouse géant auxquels il faut ajouter les services de Stockage S3, DynamoDB est un service AWS géré pour bases de données NoSQL et le service Data Pipeline qui est une sorte d’ETL sans le T et qui fournit des fonctions d’orchestration.
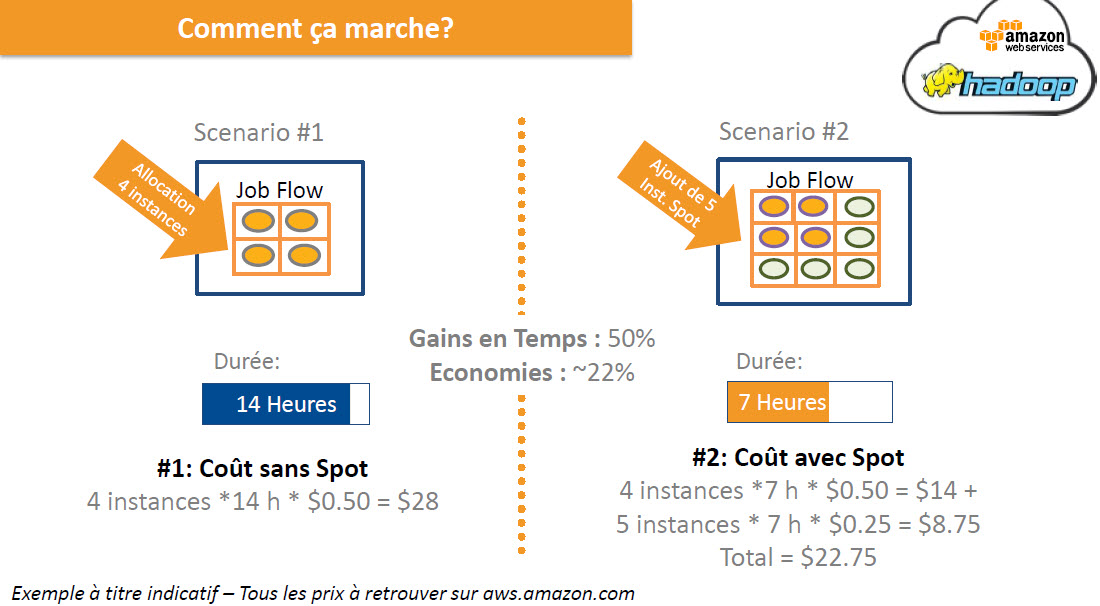
Vient ensuite le dimensionnement de la solution retenue. AWS propose plusieurs voies possibles pour optimiser en fonction des objectifs recherchés et des coûts. Il est par exemple possible de s’appuyer sur un nombre d’instances de base achetées à un prix catalogues et de fixer un prix de référence pour acheter des instances spot. De ce point de vue, AWS fonctionne un peu comme une bourse avec des prix fluctuant au rythme des offres et des demandes. Un utilisateur pourra donc fixer un prix plafond et acheter des instances lorsque le prix du marché spot passe en dessous.

 puis
puis