
La plateforme de données de Databricks s’enrichit d’un nouvel outil très attendu d’ingestion, de transformation et d’orchestration des donnés : LakeFlow.
Databricks avait beaucoup de choses à annoncer à sa conférence « Data+AI Summit 2024 » à commencer par de nouveaux outils IA pour enrichir sa plateforme « Mosaic AI » ainsi qu’une refonte totale de sa plateforme Data pour la rendre (enfin!) entièrement « Serverless ». Mais l’annonce la plus attendue était sans aucun doute LakeFlow, une brique d’ingénierie des données essentielle à toute plateforme de données dignes de ce nom.
Jusqu’ici, Databricks avait soigneusement évité d’investir le champ de l’ingestion et de la transformation de données, laissant ces fonctionnalités à ses partenaires tels que les spécialistes du domaine comme dbt (Data Build Tool), Coalesce.io ou encore Fivetran.
Mais la pression de la concurrence et surtout celle de ces clients pour réduire les coûts, consolider les services, et gagner en cohésion ont eu raison de cette volonté de laisser de la place aux partenaires. Bien évidemment ces derniers pourront toujours faire prévaloir leur richesse fonctionnelle, leur maturité et le nombre impressionnant de connecteurs disponibles. Mais la solution intégrée de Databricks répondra néanmoins au plus grand nombre.
Ainsi, Databricks a donc officialisé son service serverless « LakeFlow » pour non seulement simplifier l’ingestion de données depuis des systèmes silotés et parfois ancestraux mais aussi transformer les données et en gérer la qualité au travers de pipelines gérés de façon centralisée.
A terme, LakeFlow comprendra concrètement trois modules :
* LakeFlow Connect : Fruit du rachat d’Arcion l’an dernier, cet outil d’ingestion se veut simple et évolutif tout en offrant une forte intégration avec Unity Catalog pour la gouvernance des données ingérées. Unity Catalog est un catalogue de métadonnées en open source permettant une gouvernance unifiée des données tout en les découvrant, les gérant et les sécurisant depuis une interface centrale.
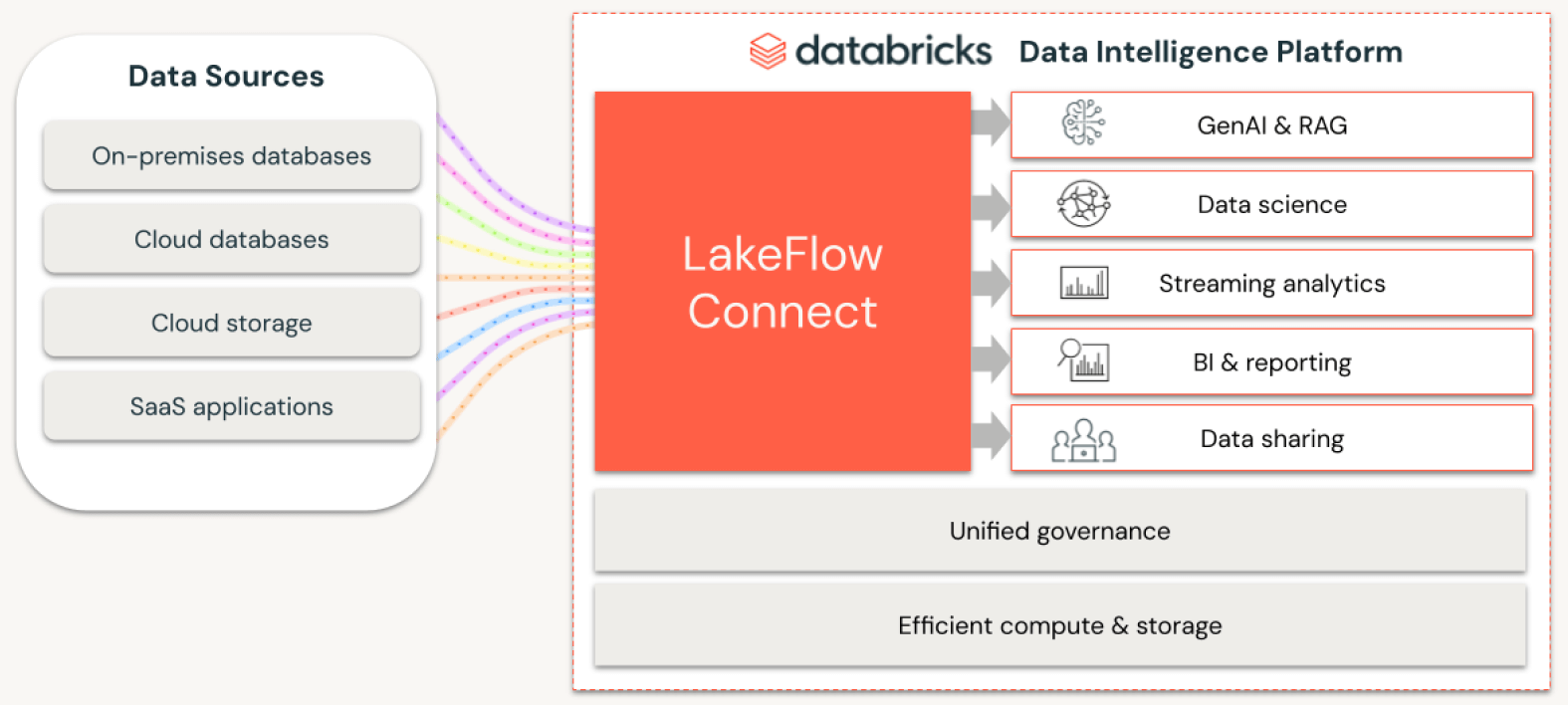
* LakeFlow Pipelines permet d’implémenter des transformations de données façon ETL/ELT en SQL ou en Python.
* LakeFlow Jobs permet l’orchestration des tâches, la gestion des anomalies, la récupération de données, etc.
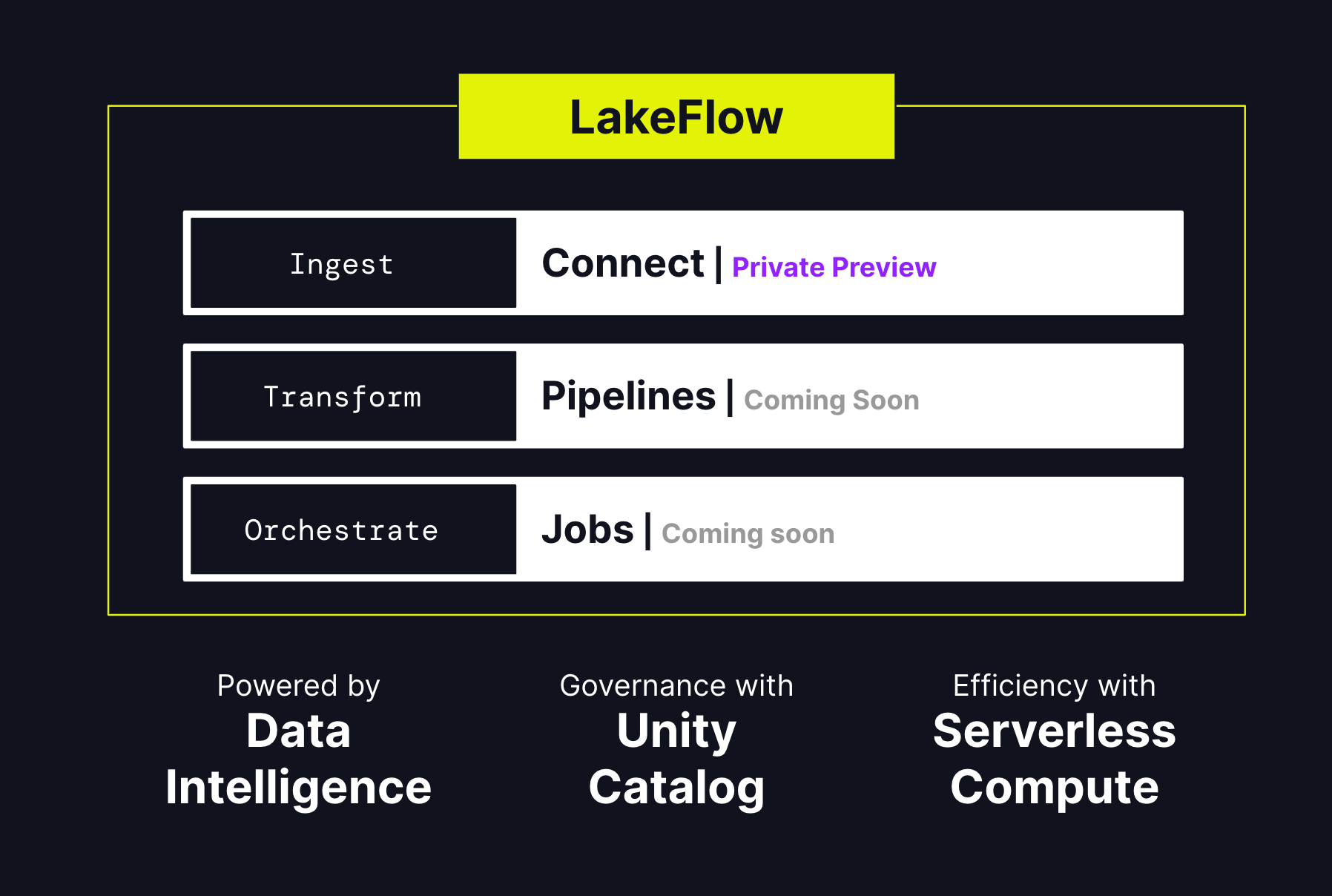
LakeFlow est encore en cours de développement. LakeFlow Connect est actuellement en Preview privée. Les deux autres modules sont attendus en preview dans les prochains mois.

 puis
puis