
Après les previews partielles annoncées fin Décembre pour déstabiliser la semaine médiatique d’OpenAI, Google repart à la charge et annonce le déploiement désormais complet de sa famille Gemini 2.0. Cette nouvelle famille de modèles IA conçus pour offrir rapidité, performance et économies d’échelle se veut spécialement pensée pour l’ère agentique. Ces outils, désormais accessibles via l’application Gemini et les plateformes Google AI Studio et Vertex AI, démontrent les progrès réalisés par le géant américain désormais sur les talons d’OpenAI.
Satisfait du lancement expérimental de Gemini 2.0 Flash en décembre dernier, le géant américain Google poursuit et accélère la généralisation de ses nouveaux modèles IA auprès d’un large public. Des modèles « conçus pour l’ère des Agents IA« ; plus aboutis, dotés de capacités de raisonnement mais surtout remarquables par leur efficacité économique. Avec Gemini 2.0, Google sort l’artillerie lourde pour renforcer sa position de leader dans la conception d’agents IA capables de comprendre et d’interagir avec un volume d’informations sans précédent.
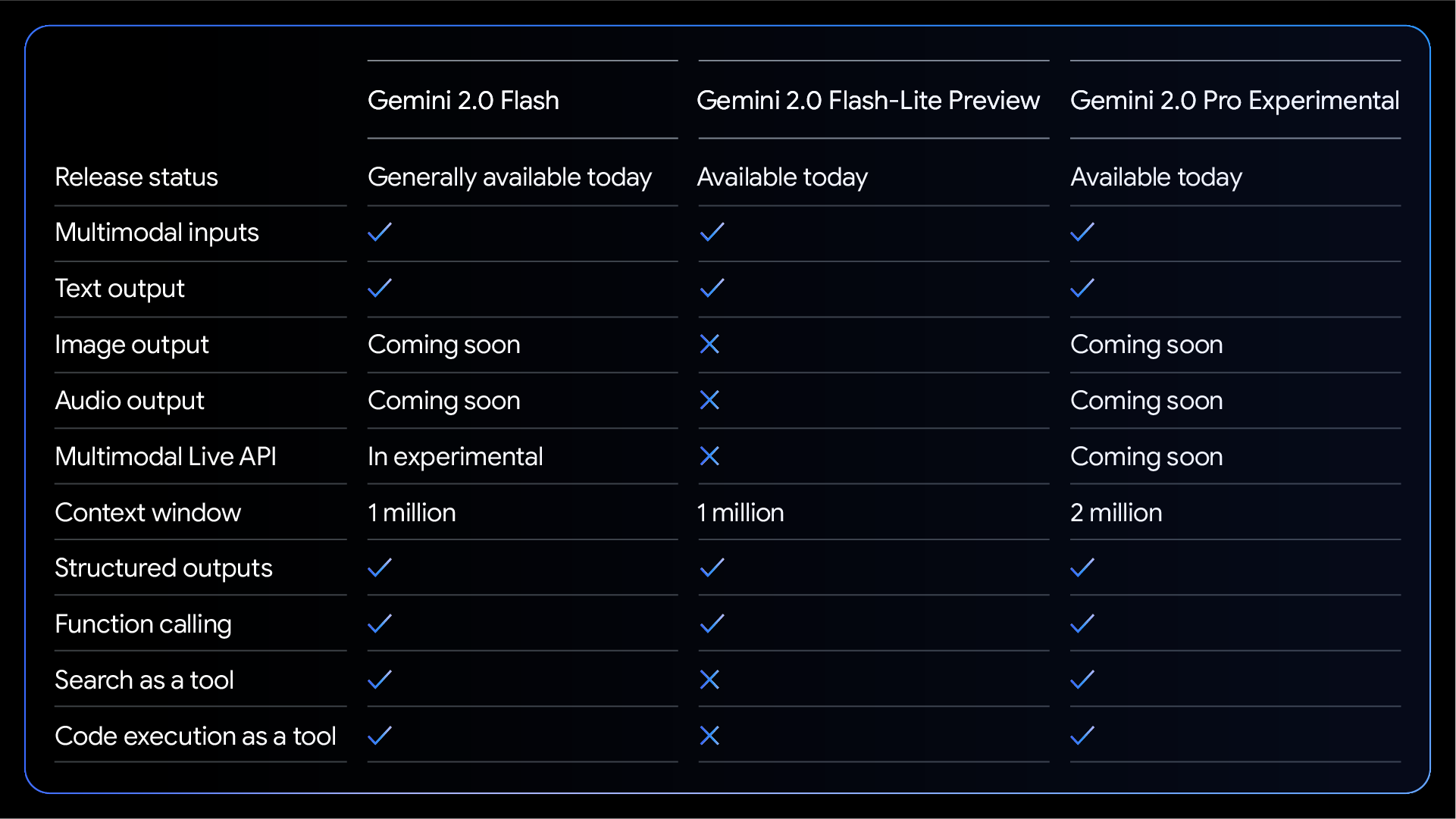
Gemini 2.0 Flash : la performance à grande échelle
Réputé pour sa rapidité et son efficacité, Gemini 2.0 Flash demeure le modèle pilier de cette nouvelle génération. Conçu pour traiter des volumes de données bien supérieurs à la concurrence – grâce à une fenêtre contextuelle d’un million de tokens -, ce modèle est désormais accessible en version finale à tous les utilisateurs via l’application Gemini, aussi bien sur desktop que sur mobile.
Les développeurs peuvent également intégrer ce modèle dans leurs propres applications IA via l’API disponible sur Google AI Studio et Vertex AI, afin de leur procurer une latence réduite et un traitement plus optimisé des requêtes. Flash 2.0 est facturé 0,10$ par million de tokens en entrée et 0,40$ par million de tokens en sortie! Preuve que, après la folie médiatique DeepSeek de la semaine dernière, les américains aussi peuvent faire des modèles à très faibles coûts d’inférence !
Gemini 2.0 Pro Experimental : codage et tâches complexes
Pour répondre à des besoins plus exigeants, où la vitesse de réponse n’est pas aussi clé à la qualité des interactions, notamment dans les domaines de l’assistance à la programmation ou aux défis scientifiques, Google lance son « Gemini 2.0 Pro Experimental » qui se démarque de Gemini 2.0 Flash par sa capacité à gérer des prompts complexes et à exceller dans la génération de code.
Doté d’une fenêtre contextuelle étendue à 2 millions de tokens (nouveau record du marché), ce modèle permet d’analyser et d’intégrer des ensembles de données massifs tout en interagissant avec des outils externes comme Google Search ou des systèmes d’exécution de code.
Disponible pour les développeurs via Google AI Studio et Vertex AI, ainsi que pour les abonnés de Gemini Advanced, il promet une compréhension et un raisonnement inégalés dans le domaine de l’IA. On appréciera au passage l’effort de Google pour assurer un accès international à ce nouveau modèle. Une fois n’est pas coutume dans l’univers de l’IA venue d’Outre-Atlantique, nous, européens et français, y avons accès en même temps que les anglo-saxons !
Gemini 2.0 Flash-Lite : L’IA ultra-économique
Apparemment, Google a – pour l’instant – jeté l’éponge sur ses modèles frontières « Ultra ». La génération 1.5 n’y avait pas eu droit, et tout porte à croire que la génération 2.0 en sera également dépourvue. On sait que les modèles gigantesques ont atteint un plateau et n’ont pour l’instant aucune justification économique tant les modèles plus compacts se montrent agiles.
Alors Google préfère focaliser ses efforts sur l’autre côté du spectre; celui des SLM. Souhaitant offrir une solution performante à moindre coût pour bouleverser un peu plus le marché et balayer DeepSeek-R1 des équations, Google annonce Gemini 2.0 Flash-Lite, le modèle le plus économique de sa nouvelle gamme. Ce dernier reprend les atouts de son prédécesseur tout en améliorant la qualité de ses résultats, sans impacter la rapidité d’exécution. Google explique que comme Flash 2.0, Flash Lite 2.0 dispose d’une fenêtre de contexte d’un million de tokens et d’une entrée multimodale. Disponible en préversion publique sur Google AI Studio et Vertex AI, Flash-Lite s’adresse notamment aux applications nécessitant un traitement extrêmement rapide et efficace de contenus multimodaux, à des tarifs ultra-compétitifs. Par exemple, il peut générer une légende pertinente d’une ligne pour environ 40 000 photos uniques, pour moins d’un dollar via Google AI Studio.
Flash-Lite 2.0 est facturé 0,075$ par million de tokens en entrée, et 0,30 dollars par million de tokens en sortie.
Gemini 2.0 Flash Thinking Experimental : Vive la transparence
Si d’une manière générale les modèles Gemini 2.0 améliorent leur capacité de raisonnement, ce ne sont pas de vrais modèles à raisonnement comme DeepSeek R1 ou OpenAI o1/o3. Mais Google y travaille ardemment. C’est tout le thème de son modèle « Gemini 2.0 Flash Thning Experimental » lancé il y a quelques semaines. Ce modèle à raisonnement dérive du modèle Gemini 2.0 Flash mais prend le temps de réfléchir avant de répondre grâce à tout une phase préliminaire de type « Chain of Thought ».
Tout comme OpenAI en début de semaine, Google – inspiré par DeepSeek – a décidé d’afficher plus de transparence sur cette phase préliminaire de réflexion. L’éditeur a en effet actualisé Gemini 2.0 Flash Thinking Experimental dans son assistant Gemini pour exposer le processus de réflexion du système, permettant ainsi aux utilisateurs de suivre le cheminement de « pensées » qui mène à chaque réponse. Cette fonctionnalité, désormais intégrée aussi bien dans l’application Gemini sur desktop que sur mobile, vise à instaurer un climat de confiance et à faciliter la compréhension des décisions prises par l’IA.
Le déploiement complet de la gamme Gemini 2.0 marque une étape importante pour Google au lendemain du tsunami médiatique engendré par la sortie de DeepSeek-R1 depuis 15 jours. En combinant des performances accrues, une fenêtre contextuelle record et une offre adaptée aux différents besoins – qu’il s’agisse de rapidité opérationnelle, de traitement de tâches complexes ou de maîtrise des coûts – Google espère ouvrir la voie à une adoption encore plus large et plus efficace de l’IA dans tous les domaines.

 puis
puis