
La première phase d’Hadoop était orienté batch. La seconde dans laquelle on entre aujourd’hui est orientée interactif et temps réel.
Tous les investissements dans le big data ne sont pas sur Hadoop, mais ce dernier constitue sans aucun doute le principal pilier de cette nouveau domaine qui élargit considérablement le périmètre de la business intelligence. Rappelons qu’Hadoop est un framework Java permettant de créer des applications distribuées « scalables », c’est-à-dire supportant des milliers de nœuds et des Po de données. Depuis 2009, Hadoop est un projet sous la responsabilité de la fondation Apache. Hadoop n’est donc pas un logiciel mais un ensemble d’applications destiné à analyser des volumes considérables de données et à en extraire des tendances.
A sa création, avec MapReduce, Hadoop était orienté batch, c’est-à-dire qu’il permettait de d’effectuer des calculs parallèles, et souvent distribués, de données potentiellement très volumineuses. « Depuis, Hadoop a élargi ses sphères d’intervention pour aller sur le terrain de l’interactif (temps de réponse compris entre 30 ms et 10 minutes) et du temps réel (temps de réponse inférieur à 30 ms) », explique Nick Heudecker, analyste du Gartner
Hadoop 2, sorti en octobre dernier, apporte avec Yarn (Yet-Another-Resource-Negotiator) la possibilité de construire des applications de traitement de données fonctionnant nativement sur Hadoop. Yarn permet de séparer la problématique de la gestion des ressources des clusters de celle du traitement des données. C’est cette séparation qui rend possible l’utilisation de nouvelles solutions qui peuvent exploiter les données gérées par le système de fichier HDFS (Hadoop Distributed File System) développé à partir du GoogleFS (Google File System) et administrées par Yarn.
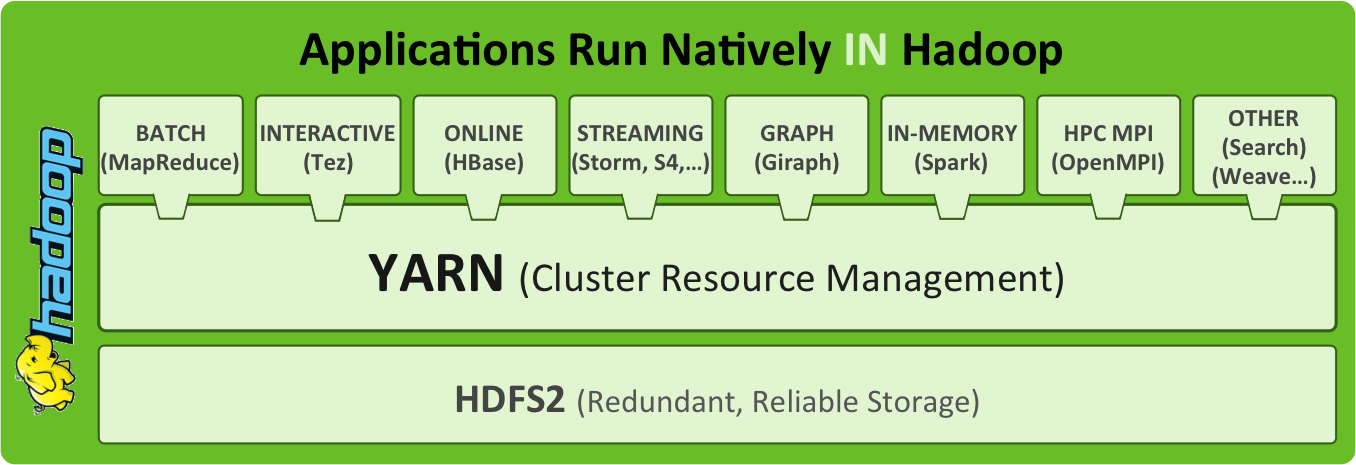
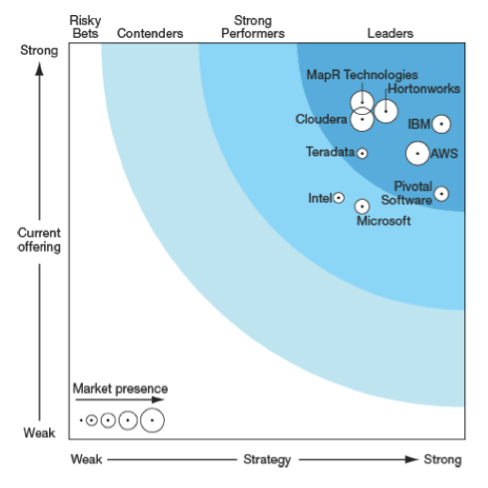
Comme il est d’usage dans le monde de l’open source, les fournisseurs proposent leur propre distribution d’Hadoop dans laquelle ils assurent l’intégration des composants qu’ils ont retenus et auxquels ils peuvent ajouter des éléments propriétaires. Les trois distributions les plus couramment répondues sont celles de MapR, Cloudera et HortonWorks mais il en existe d’autres. Dans une étude récente, le cabinet Forrester classe neuf fournisseurs de solutions Hadoop – voir infographie ci-dessous – en fonction de 32 critères (The Forrester Wave: Big Data Hadoop Solutions, Q1 2014).
Hadoop est une technologie relativement jeune et encore assez peu utilisée dans les entreprises pour des projets réels. Parmi les motivations pour lancer de tels projets, c’est, selon le Gartner, l’amélioration de l’expérience clients qui est citée le plus souvent cités par les entreprises, devant l’efficacité des processus et la conception de nouveaux produits ou services ou de nouveaux business models. Viennent ensuite la réduction des coûts, l’amélioration de la gestion des risques, la valorisation des données disponibles, la conformité aux réglementations et l’amélioration de la sécurité. Sachant que la grande majorité des entreprises démarrent avec des données disponibles en interne avant de s’aventurer avec des données collectes auprès de sources externes ou spécialement pour ces projets.
Dix startups (9 américaines et 1 israélienne) dans le big data
| Nom | Date de création | Financement (en M$) |
Activité | Concurrents |
| Platfora | 2011 | 65 | Transfère des données Hadoop en une solution de business intelligence in-memory sans ETL ni data warehouse | Datameer, tableau, IBM, SAP, SAS, Alpine Data et Rapid-I |
| Alpine Data Labs | 2010 | 23,5 | Permet de manipuler des données de manière visuelle sans avoir à développer du code | Nuevora, PLatfora, Skytree, Revolution Analytics, Rapid-I |
| Altiscale | 2012 | 12 | Fournit un service Hadoop as a service destiné à masquer la complexité de cette solution | Elastic MapReduce d’Amazon, Hadoop on Azure de Microsoft, HortonWorks sur Rackspace |
| Trifacta | 2012 | 16 | Manipulation des données de manière visuelle | Paxata, Informatica, CirroHow |
| Splice Machine | 2012 | 19 | Propose le meilleur des deux mondes avec les bases de données NoSQL et les bases SQL | Cloudera, MemSQL, NuoDB, Datastax, VoltDB |
| DataTorrent | 2012 | 8 | Met l’accent sur les performances | IBM (Infosphere Streams) et Storm |
| Qubole | 2011 | 7 | Développe une interface utilisateur pour faciliter l’usage des technologies Hadoop | Altiscale, Amazon EMR, Treasure Data |
| Continuuity | 2011 | 12,5 | Propose une plate-forme d’hébergement pour les développeurs Java | AWS EMR, Altiscale, Infochimps, Mortar Data |
| Xplenty | 2012 | NC | Traitement Hadoop sur le cloud | AWS EMR, Altiscale, Mortar Data, Qubole, Hadoop on Azure |
| Nuevora | 2011 | 3 | Développe des algorithmes sur des sources disparates de données | Accenture, Alpine Data Labs |
(Source CIO : 10 Hot Hadoop Startups to Watch)

 puis
puis