
Meta ne cesse de peaufiner son LLM « LLama 3 », le mètre étalon des modèles dits « ouverts » avec des itérations qui se succèdent à grande vitesse. La version « 3.3 » améliore significativement les capacités de raisonnement du modèle.
Les acteurs majeurs de l’IA semblent rencontrer de grandes difficultés à continuer de faire monter à l’échelle leurs très grands modèles. Alors, en attendant de trouver l’étincelle technologique qui bridera le plafond atteint, ils cherchent à peaufiner les algorithmes existants afin d’améliorer les capacités de raisonnement des modèles. On l’a vu avec Anthropic et la dernière itération de son « Claude 3.5 Sonnet », avec Google et l’annonce de « Gemini 2.0 » et bien évidemment avec Open et ses nouveaux modèles « o1 ». Et Microsoft a démontré avec Phi-4 que les capacités de raisonnement pouvaient aussi se décliner sur les SLM, les petits modèles IA.
Meta semble emprunter la même voie avec sa famille de modèles « Llama ». L’éditeur vient d’officialiser « Llama 3.3 70B Instruct », un modèle de langage multilingue qui se distingue par son architecture « transformer » optimisée, sa capacité à être personnalisé par les entreprises et sa fenêtre de contexte étendue à 128 000 tokens.
LLama 3.3 70B demeure un modèle textuel uniquement, supportant l’anglais, l’allemand, le français, l’italien, le portugais, l’espagnol, l’hindi et de thaïlandais.
L’architecture du modèle, qui comprend 70 milliards de paramètres, intègre une innovation technique majeure avec l’Attention à Requêtes Groupées (GQA – Grouped-Query Attention). Selon Meta, cette approche améliore considérablement l’efficacité computationnelle et la scalabilité du système.
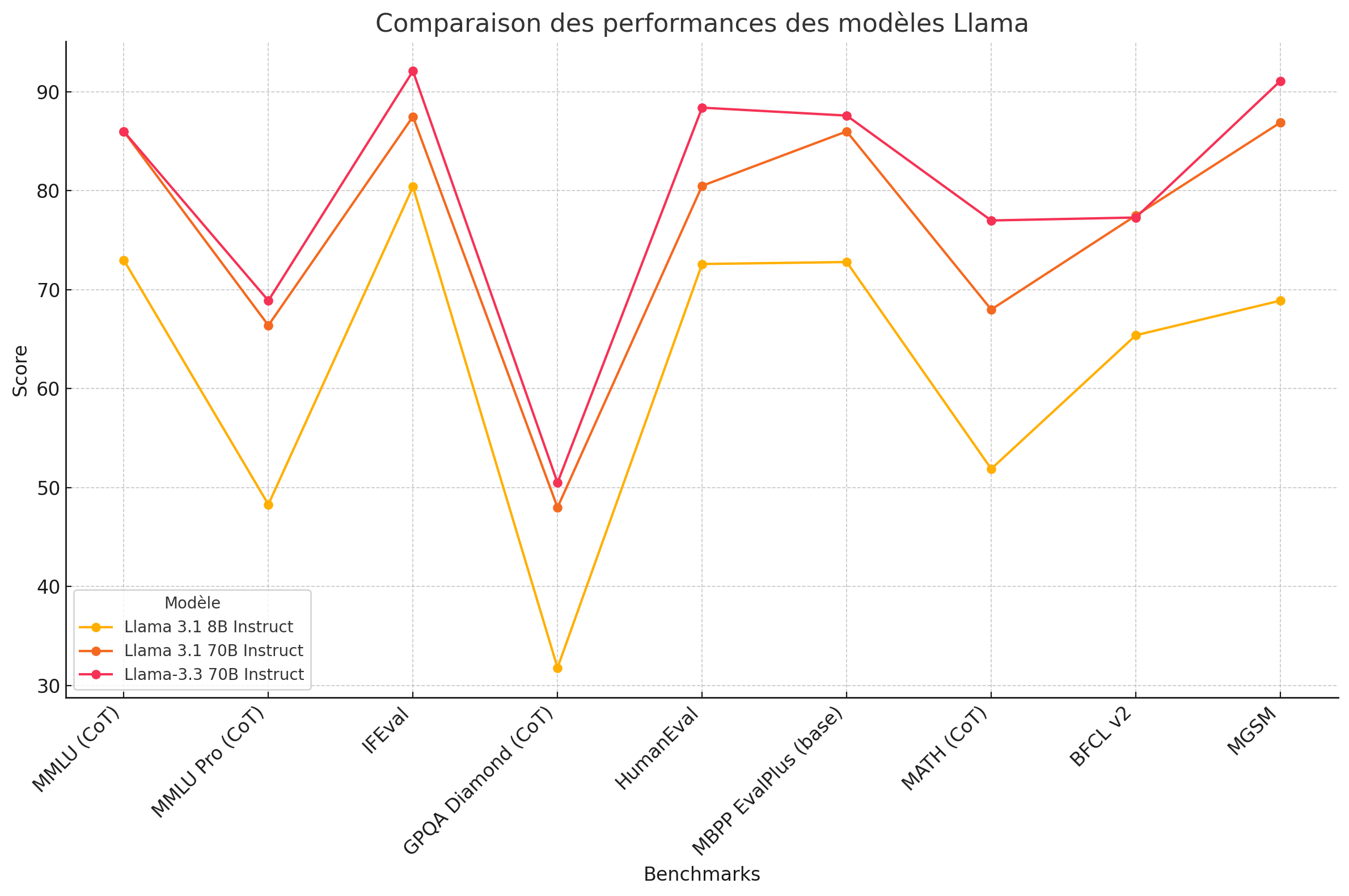
Les performances de Llama 3.3 présentent un gain notable sur les itérations précédentes. Le modèle atteint notamment une précision de 50,5% sur le benchmark GPQA pour le raisonnement, et excelle dans la génération de code avec un score de 88,4% au test HumanEval.
Meta a accordé une attention particulière à la sécurité dans le développement de Llama 3.3, en implémentant des stratégies robustes de refus pour les requêtes potentiellement dangereuses. Le modèle est disponible sous la licence communautaire Llama 3.3, avec des points de contrôle hébergés sur Hugging Face, permettant aux développeurs d’exploiter des versions quantifiées pour optimiser les ressources matérielles.
Au chapitre des bonnes initiatives, Meta fait preuve d’une certaine transparence « durable » en précisant que le modèle a été entraîné sur l’un de ses clusters maison à partir d’un ensemble de données composé de 15 000 milliards de tokens, a nécessité 7 millions d’heures de calcul GPU sur des cartes GPU NVidia H100-80GB et engendré 2.040 tonnes d’émission de CO2 malgré l’usage de 100% d’énergie renouvelable, des émissions compensées par les efforts parallèles de Meta pour rester au final sur de la neutralité carbone.
On rappellera néanmoins que, même si Meta n’est pas d’accord, son modèle LLama 3.3 « ouvert » n’est pas considéré comme un modèle « open source » selon la définition officielle de l’OSI.
LLama 3.3 va rapidement se retrouver déployer sur à peu près toutes les plateformes IA du marché mais les modèles sont déjà sur Hugging Face : meta-llama/Llama-3.3-70B-Instruct · Hugging Face

 puis
puis