
Alors qu’OpenAI joue la compacité de son GPT-4o mini, Meta gonfle son modèle LLama 3 dans une variante qui fait de l’ombre aux LLM frontières que sont GPT-4o et Claude 3.5 Sonnet. Une étape marquante pour les modèles en open-source.
LLama de Meta est la référence absolue des modèles LLM en open-source, le mètre-étalon sur lequel tous les concurrents se comparent et s’évaluent. Plus important encore, LLama est le modèle open-source que tout service « Model as a Service » du marché se doit d’implémenter. On le trouve chez Azure AI, chez Google Vertex AI et chez AWS Bedrock notamment.
En avril dernier, Meta avait séduit bien des entreprises et des chercheurs en IA en introduisant « LLama 3 », dernière itération de son LLM aux performances annoncées proches de Claude 3 Sonnet et Gemini Pro 1.5.
Meta avait alors introduit une version « 8B » et une version « 70B » tout en promettant une version supérieure « 400B » supportant une trentaine de langues mais qui ne s’est jamais réellement concrétisée.
Cette semaine, après des premières fuites sur Reddit, Meta et son laboratoire IA « FAIR » ont officiellement annoncé « LLama 3.1 » avec une disponibilité d’un modèle « 405B » (405 milliards de paramètres) qui, si l’on en croit les benchmarks, surpasserait l’actuel leader du marché, « GPT-4o » d’OpenAI sur plusieurs tests IA réputés.
LLama 3.1 405B supporte 8 langues (Anglais, Allemand, Français, Italien, Portugais, Hindi, Espagnil, Thaï) et demeure un pur LLM textuel sans fonctionnalités multimodales (mais Meta affirme expérimenter le multimodal pour une future évolution).
Avec 405 milliards de paramètres, LLama 3.1 405B est le plus gros des modèles LLM en open source, un modèle pas vraiment économique à faire tourner en local dans son datacenter. Il a été entraîné sur 15 000 milliards de tokens issus de sources d’information jusqu’en janvier 2024.
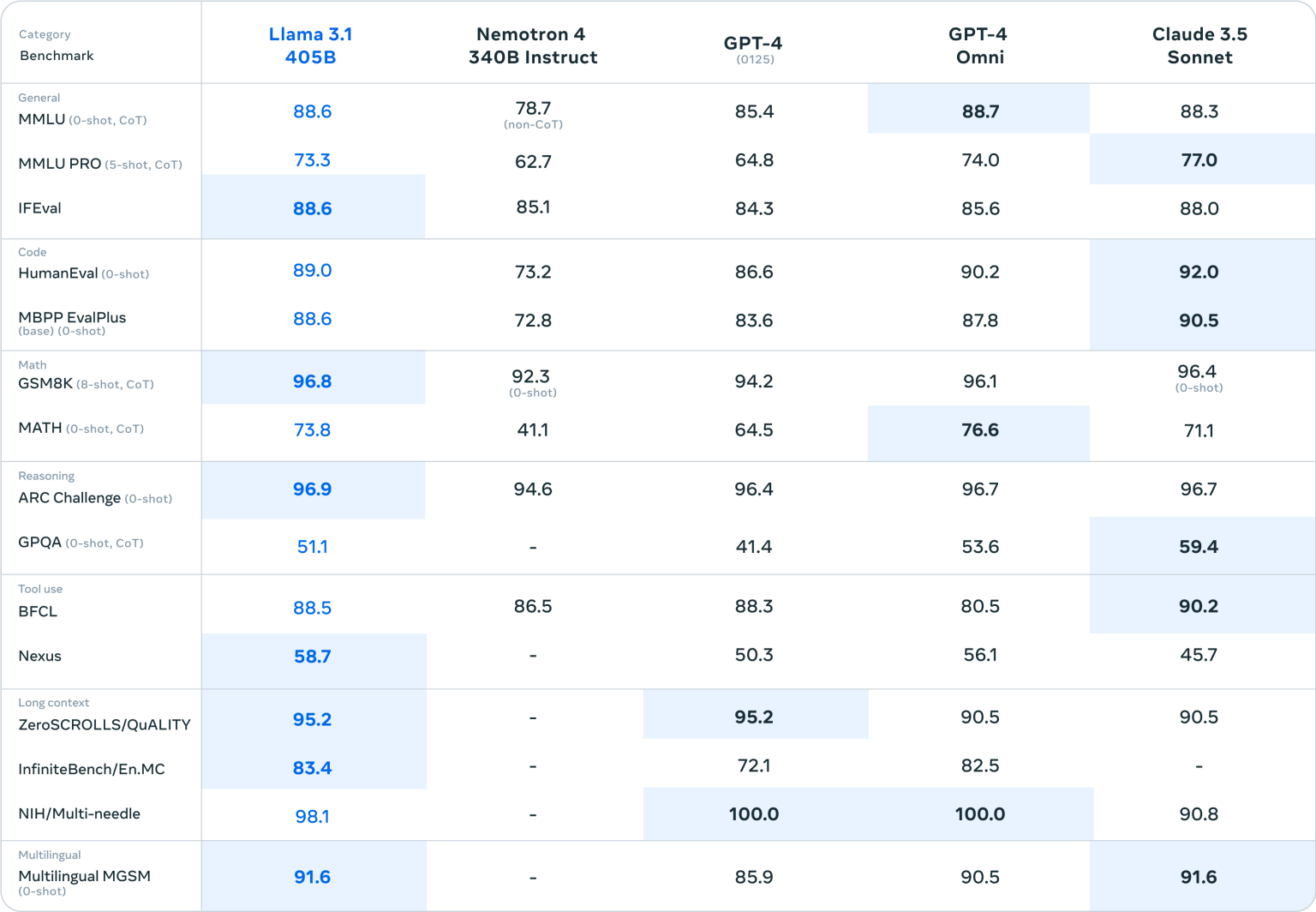
D’après les benchmarks publiés, c’est la première fois qu’un modèle open source rivalise d’aussi près avec les meilleurs modèles « frontières » du marché.
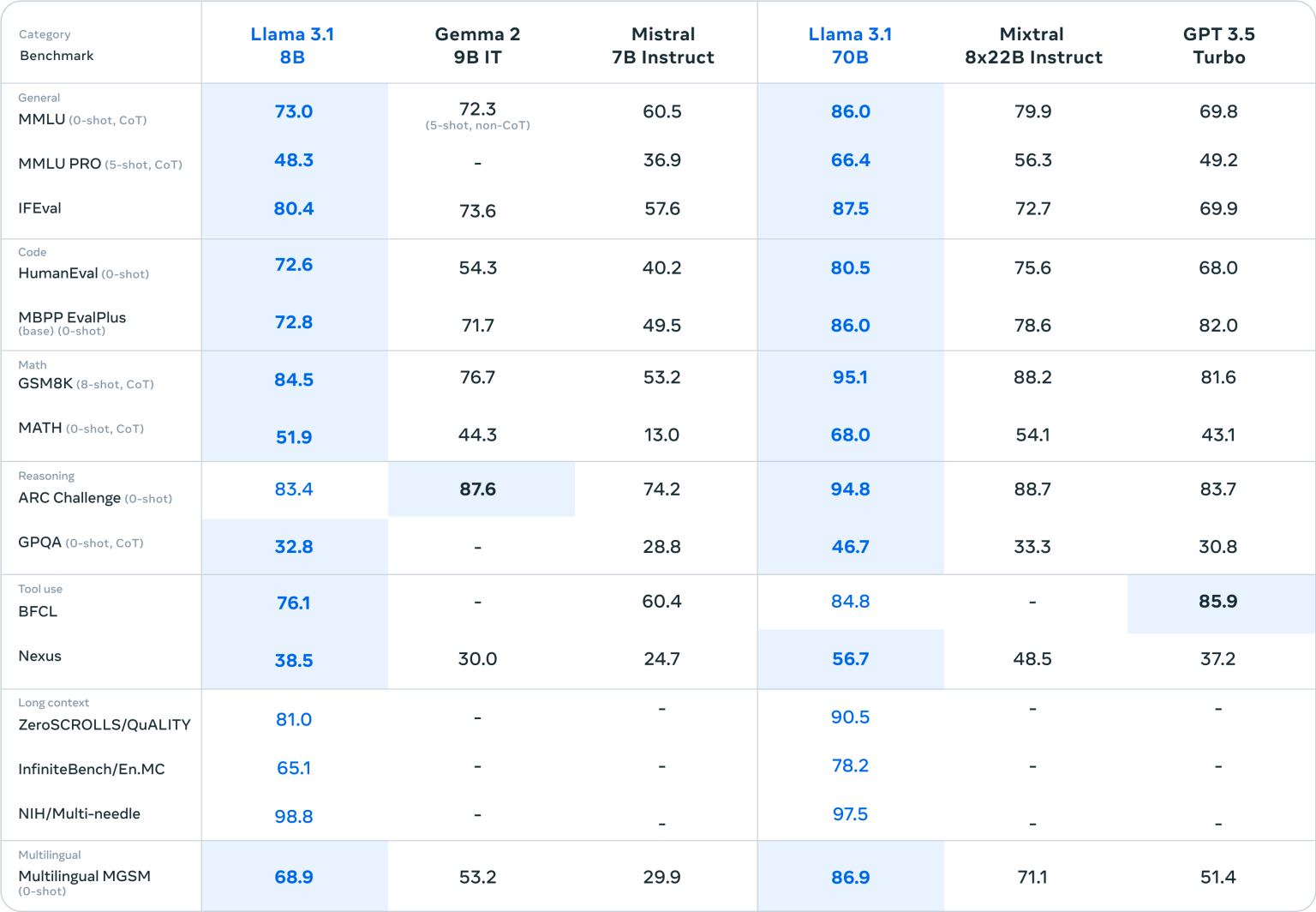
Au passage on notera également que les modèles LLama 3.1 8B et LLama 3.1 70B progressent eux aussi très significativement notamment dans des domaines comme le raisonnement mathématique ou la génération de code informatique.
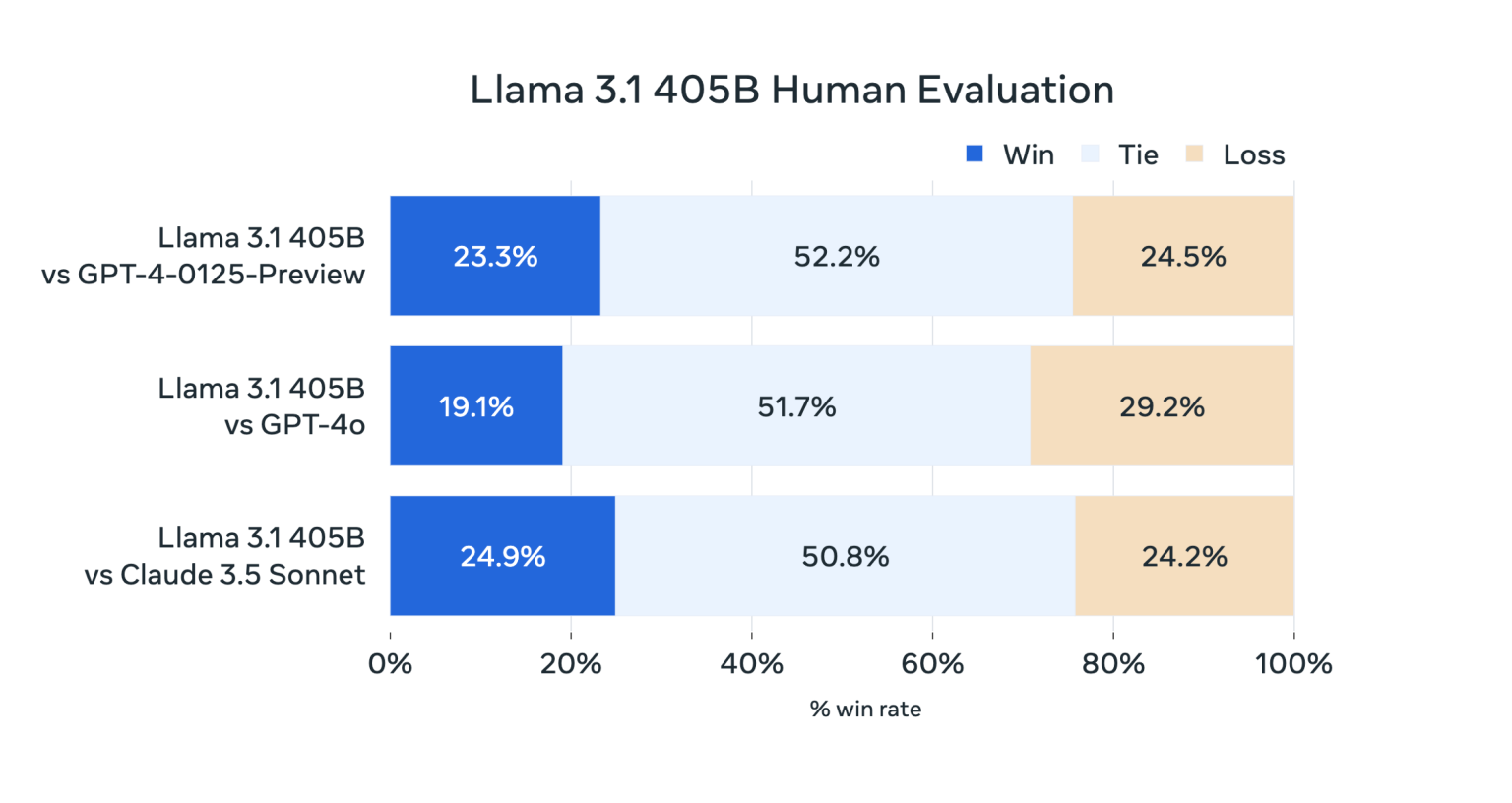
Ces résultats nous inspirent deux réflexions :
Tout d’abord, les modèles moyens comme « LLama 3.1 70B » et « GPT-4o mini » semblent désormais rivaliser en pertinence avec les très grands modèles tout en étant bien plus faciles et moins onéreux à opérer.
Ensuite, ce saut qualitatif réalisé avec « LLama 3.1 » doit forcément interpeler et inquiéter des concurrents de l’univers open source comme Mistral AI. Certes, la jeune pousse française ne s’en laisse pas compter. Son modèle « Mistral 7B » est considéré comme un modèle de référence aisément exécutable en local. Et la jeune pousse vient de lancer, avec « Mistral NeMo 12B », sa nouvelle génération destinée à remplacer « Mistral 7B » dans les applications IA d’entreprise. La concurrence de « LLama 3.1 8B » s’annonce néanmoins féroce.
En attendant force est de reconnaître que l’innovation IA est toujours aussi effervescente et que, mois après mois, les progrès sont sensibles et visibles nous rapprochant doucement mais surement d’IA véritablement très utiles voire d’IA générales (les AGI).
Mise à jour du 23/07/2024 :
L’article original a été publié quelques heures avant l’officialisation du lancement de Llama 3.1. L’article a été modifié avec les informations officielles publiées par Meta.
À lire également :
Chérie, j’ai rétréci GPT-4o…
GPT-4o : Un peu plus près de HAL et 2001…
Anthropic lance Claude 3.5 annoncé meilleur que GPT-4o
OpenAI se passe d’observateurs Microsoft ou Apple dans son Board
Project Astra : la réponse de Google à ChatGPT 4o

 puis
puis