
Surprise, pour sa dernière annonce de l’année, OpenAI a dévoilé ses modèles « OpenAI o3 », des modèles à raisonnement qui vont succéder aux récents « o1 » mais ne sont pour l’instant réservés qu’aux chercheurs en IA qui devront en vérifier la bienveillance…
Il y a un près de deux semaines, OpenAI commençait ses 12 jours d’annonce par l’officialisation de ces modèles « OpenAI o1 » disponibles jusque-là en preview. Un « o1 » fonctionnellement plus limité que le modèle « GPT 4-o » mais doté de capacités de raisonnement, et notamment de raisonnement mathématique et scientifique bien supérieurs à « GPT 4-o » mais aussi très significativement supérieure à « o1 preview » !
Et pour clôturer ses 12 jours d’annonces, OpenAI a levé le voile sur « OpenAI o3 » le modèle qui succèdera à « o1 » !
Mais où est donc passé « o2 » vous demandez-vous probablement ? OpenAI saute une numérotation pour éviter tout problème légal avec la marque « O2 » qui appartient à l’opérateur Telefonica. Et puis ça évite aussi les conflits avec le français éponyme spécialisé dans les services à la personne et toute confusion dans les moteurs de recherche avec la formule chimique du dioxygène !
Tout comme « o1 », « o3 » se distingue des modèles classiques comme « GPT 4-o » par sa capacité à raisonner avant de répondre et notamment d’évaluer la pertinence de que ce qu’il veut répondre avant de répondre.
Ce qui distingue « o3 » de « o1 » c’est la possibilité d’ajuster son temps de réflexion en fonction de la complexité du problème posé. Autrement dit, il est possible de demander à « o3 » de fonctionner en mode « low », « medium » ou « high compute ».
En outre, les modèles « o3 » sont apparemment plus rapides que les modèles « o1 ».
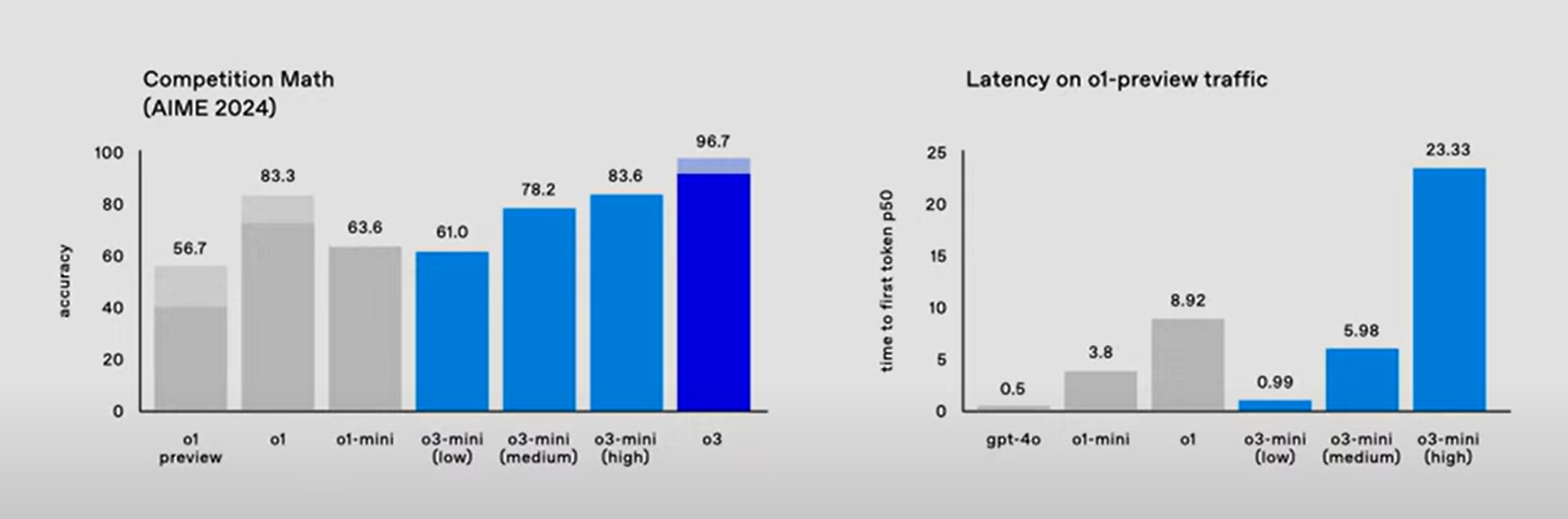
Le modèle « o3-mini » est pour l’instant uniquement accessible à des testeurs et chercheurs triés sur le volet. Le modèle « o3 » le sera plus tard en 2025.
Un modèle qui raisonne est-il plus dangereux ?
Pour l’instant OpenAI n’avance aucune date d’arrivée de « o3 » sur sa plateforme API et sur ChatGPT. Car le modèle va avoir besoin d’être contrôlé plus intensément que les autres. Jeudi dernier, Anthropic dévoilait que les derniers LLM pouvaient en quelque sorte « cacher » leurs intentions. Or il semblerait que ce soit encore plus vrai avec « o1 », autrement dit que le modèle semble se conformer aux instructions de conformité inculquées mais ce n’est qu’une apparence et en le poussant dans ces derniers retranchements dévoile une « personnalité » ancrée dans son jeu d’apprentissage historique éloignée des instructions de conformité. Dans la plupart des cas, les modèles qui ont ainsi été pris en flagrant délit de mensonge (présentant des fausses informations tout en « sachant » que ces informations sont fausses) l’on fait pour « faire plaisir » à l’utilisateur (et non bien évidemment pour servir leurs propres dessins).
Alors que, selon les rumeurs, OpenAI serait pour l’instant déçu par ses préversions de Orion/GPT-5 (trop coûteuses à opérer pour une amélioration marginale), la jeune pousse constate des progrès plus significatifs avec ses « modèles raisonnants ». Selon les responsables, « o3 » marque « une percée significative » sur les benchmarks IA les plus complexes d’OpenAI.
Un avis partagé par François Chollet (ex Google AI), co-créateur d’un benchmark ARC-AGI destiné à évaluer la capacité des systèmes d’intelligence artificielle à généraliser et à acquérir de nouvelles compétences en dehors de leur entraînement initial. Dans un tweet il explique « nous avons collaboré avec OpenAI pour le tester sur ARC-AGI, et nous pensons qu’il représente une avancée significative dans la capacité de l’IA à s’adapter à de nouvelles tâches. Il obtient un score de 75,7 % sur l’évaluation semi-privée en mode low-compute et 87,5% en mode high-compute ». Il ajoute d’ailleurs que ces capacités représentent un nouveau territoire et elles exigent une attention scientifique sérieuse.
Il considère néanmoins que « o3 » n’atteint pas encore le stade « AGI » (Intelligence artificielle générale) notamment parce que le modèle échoue (tout en dépensant des milliers de dollars de consommation de ressources) sur certains tests triviaux pour les humains du bench « ARC-AGI 1 » et qu’il est encore loin d’afficher un score significatif sur le futur test « ARC-AGI 2 ». Le truc, c’est que des modèles comme « o3 » sont « intelligents » mais « raisonnent » de façon différente de l’être humain.
Quoiqu’il en soit, si 2024 a été l’année des petits LLM, les SLM, 2025 s’annonce déjà comme l’année des « modèles raisonnants » avec les « o1 » et « o3 » d’OpenAI mais aussi le « R1 » de DeepSeek, le QwQ d’Alibaba, le Phi-4 de Microsoft, et le « Gemini 2.0 Flash Thinking Experiment » de Google !

 puis
puis