
Hadoop est le logiciel ou plutôt la plate-forme logicielle permettant de lancer des projets des big data. Quelle distribution retenir ?
 « Avec l’avènement de Spark et de Spark Streaming, elles devront exploiter pleinement le potentiel de leurs investissements visant à créer des « lakes » et des « data warehouses » sur Hadoop », explique Laurent Bride, CTO de Talend. « Les pionniers de l’exploitation des Big Data récolteront les fruits de leurs investissements en 2016, et l’écart entre DSI à succès et perdants va considérablement s’agrandir ». « Hadoop se démarque aujourd’hui radicalement des logiciels et des bases de données historiques du marché », considère le cabinet Octo Technologies dans la toute récente publication intitulée Hadoop feuille de route. Comment ? « Tout d’abord d’un point de vue technique, grâce à une architecture repensée pour le stockage et le calcul distribué. La démarcation se fait également d’un point culturel, Hadoop est en effet le produit d’une large communauté open source ».
« Avec l’avènement de Spark et de Spark Streaming, elles devront exploiter pleinement le potentiel de leurs investissements visant à créer des « lakes » et des « data warehouses » sur Hadoop », explique Laurent Bride, CTO de Talend. « Les pionniers de l’exploitation des Big Data récolteront les fruits de leurs investissements en 2016, et l’écart entre DSI à succès et perdants va considérablement s’agrandir ». « Hadoop se démarque aujourd’hui radicalement des logiciels et des bases de données historiques du marché », considère le cabinet Octo Technologies dans la toute récente publication intitulée Hadoop feuille de route. Comment ? « Tout d’abord d’un point de vue technique, grâce à une architecture repensée pour le stockage et le calcul distribué. La démarcation se fait également d’un point culturel, Hadoop est en effet le produit d’une large communauté open source ».
Hadoop est un des projets open source les plus dynamiques. Selon Octo, il représente plus de 10 % des projets mis en avant par la fondation Apache (les top-level projects). Les plus gros clusters frôlent les 10 000 nœuds ; En France, c’est la société Criteo qui mène la danse avec 1 000 nœuds.
À ce jour, les 4 grands acteurs-distributeurs du paysage sont Hortonworks, Cloudera, Pivotal[1] et MapR. De grandes entreprises de l’IT, comme IBM ou Oracle, ont aussi « leur » distribution Hadoop. Elles sont, pour certaines, basées sur d’autres distributions – c’est le cas d’Oracle qui embarque Cloudera dans son appliance Big Data. Sachant qu’il est possible aussi de faire appel à Hadoop sur le cloud :
– Amazon, met à disposition un service Elastic Map Reduce (EMR) entièrement basé sur Hadoop, offrant le choix entre les distributions Apache et MapR ;
– Google offre avec Google Compute des clusters Hadoop basés sur les distributions Apache et MapR ;
– Microsoft propose HDInsight de sa plateforme Azure, montée en partenariat avec Hortonworks ;
– En France, OVH et Orange Business Services sont positionnés sur ce créneau.
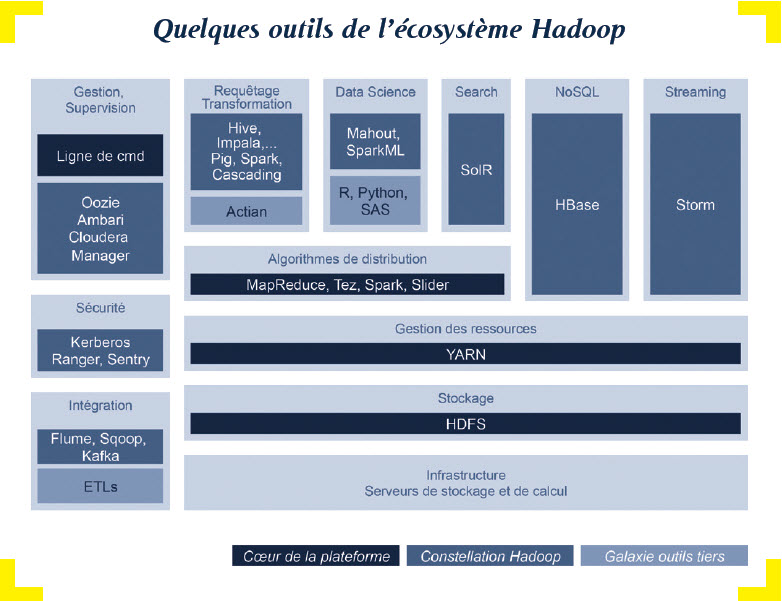
« Dans cette galaxie Hadoop, Spark n’est pas qu’un langage de transformation de données, précise Octo. C’est au départ une plateforme d’exécution distribuée, un peu comme Hadoop, et créée indépendamment de ce dernier. Depuis peu dans le giron d’Apache, il est en train de fusionner avec Hadoop pour devenir un moteur d’exécution alternatif à MapReduce, et son écosystème suit le même chemin. Son API écrite en Scala tire parti des techniques de programmation fonctionnelle, concises et particulièrement adaptées au calcul distribué. Cela explique l’intérêt considérable que la communauté Big Data et les éditeurs Hadoop portent à Spark. Sans aucun doute, une partie du futur d’Hadoop se tient là ». D’ailleurs, les 5 principales distributions Hadoop – Cloudera, Hortonworks, MapR, IBM, Pivotal – intègre toutes Spark.
Pour Mike Gualtieri and Noel Yuhanna, analyste du cabinet Forrester et auteurs de la note The Forrester Wave: Big Data Hadoop Distributions, Q1 2016 |Five Top Vendors Have Significantly Improved Their Offerings, le choix d’une solution s’avère une tâche ardue.

 puis
puis