
À l’occasion de son Cloud Data Summit, Google Cloud a annoncé la preview de BigLake, un nouveau moteur de data lake construit sur l’expérience acquise avec son datawarehouse cloud BigQuery.
L’air de rien, Google Cloud s’est taillé une belle réputation ces dernières années en tant que Data Cloud avec son datawarehouse BigQuery, ses technologies serverless Cloud Run et ses outils d’analyse ML « Vertex AI ».
Surfant sur la même volonté d’unifier lacs et entrepôts de données qui a conduit Microsoft a lancé Azure Synapse il y a un peu plus d’un an, Google Cloud annonce « BigLake » pour briser les silos qui séparent les lacs et entrepôts. Des silos synonymes de limitation des analyses, d’augmentation des risques mais aussi d’augmentation des coûts car il faut souvent dupliquer les données pour réaliser des analyses croisées.
« BigLake permet aux entreprises d’unifier leurs lacs et entrepôts de données pour analyser les données sans se soucier du format ou du système de stockage sous-jacent, éliminant ainsi le besoin de dupliquer ou de déplacer les données et réduisant les coûts et la perte d’efficience » explique l’éditeur.
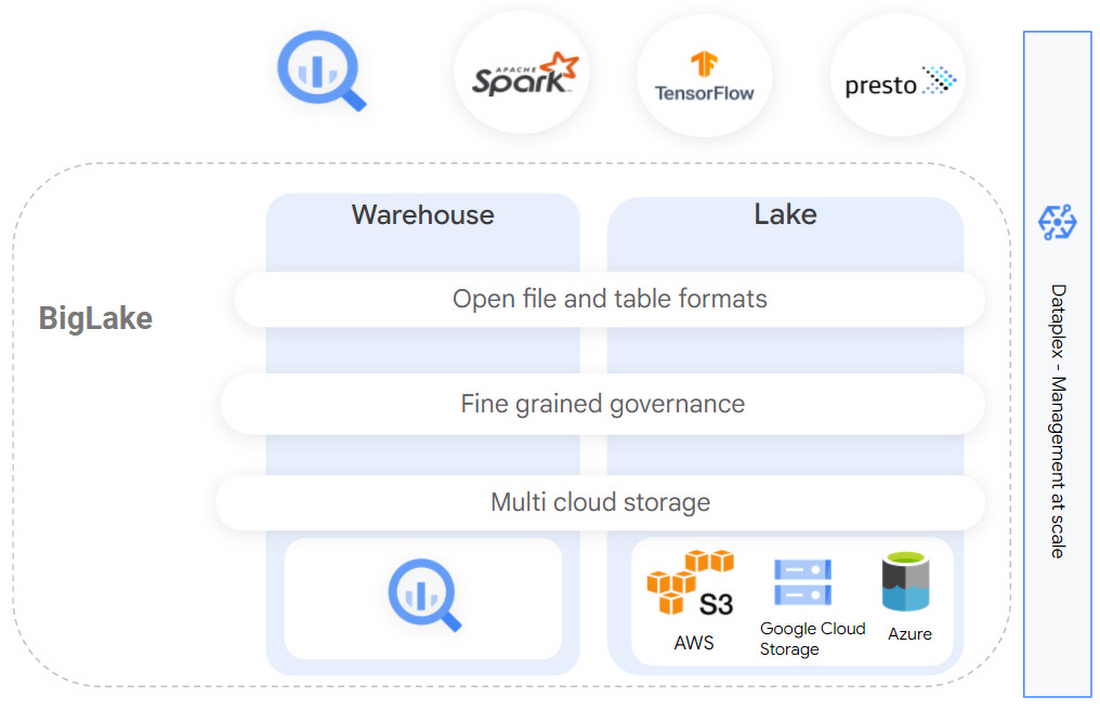
La solution est vraiment pensée dans un esprit d’unification des différents lacs de données en s’appuyant sur toute l’expérience acquise par Google Cloud mais aussi par ses clients avec BigQuery. BigLake permet ainsi non seulement de s’appuyer sur le datawarehouse BigQuery et les données qui y sont entreposées mais aussi sur des lacs stockés sur AWS S3 et sur Azure Data Lake. Le tout avec un maximum de sécurité mais aussi d’efficacité afin de réaliser des analyses avancées et d’explorer tout le potentiel du ML et de l’IA.
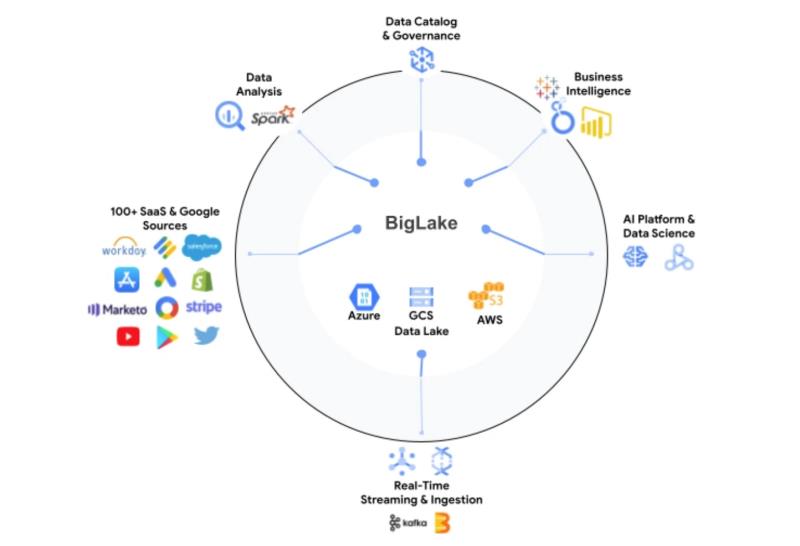
« Avec BigLake, les clients bénéficient de contrôles d’accès précis, avec une interface API couvrant Google Cloud et des formats ouverts comme Parquet, ainsi que des moteurs de traitement open-source comme Apache Spark. Ces capacités étendent les innovations apportées par BigQuery au cours des dix dernières années aux lacs de données sur Google Cloud Storage afin de créer une architecture ouverte, flexible et rentable » ajoute l’éditeur.
Parallèlement à cette annonce phare, Google Cloud a également annoncé deux nouveautés qui ne manqueront pas d’interpeller ses utilisateurs de services de données.
Une nouvelle fonctionnalité « Change Streams » permet de réaliser de la capture temps réel de changements (CDC – Change Data Capture) sur Spanner, la base de données SQL distribuée de Google Cloud. Cette fonctionnalité permet de traquer en temps réel tout changement (inserts, updates, deletes) apporté aux données et de déclencher des évènements Pub/Sub, mettre à jour des analyses, etc.
Autre nouveauté, Google Cloud annonce la disponibilité en version finale de « Vertex AI Workbench », un nouvel outil convivial et interactif pour gérer tout le cycle de vie des projets de Data Science. « Vertex AI Workbench rassemble les données et les systèmes ML dans une seule interface afin que les équipes disposent d’un ensemble d’outils communs à l’analyse de données, à la science des données et à l’apprentissage machine. Les équipes peuvent ainsi construire, entraîner et déployer un modèle ML cinq fois plus rapidement qu’elles ne le faisaient jusqu’ici » explique l’éditeur.
À lire également :
> Google Cloud Next’21 : Entre initiatives souveraines et multicloud
> Google Cloud lance trois nouveaux services Data
> Des tableaux de bord pour mesurer les émissions CO2 d’Azure et Google Cloud.
> Azure Synapse unifie data-warehouses et data-lakes
> Avec Azure Purview, Microsoft investit le marché de la gouvernance de la donnée
> La startup française Saagie étend son orchestrateur DataOps à l’international.

 puis
puis