
Le fabricant d’accélérateurs IA Cerebras annonce avoir entraîné le plus large modèle jamais ainsi formé sur une seule et unique puce. Explications…
Cerebras s’autocongratule : avec leur accélérateur et leur plateforme CSoft, il est possible d’entraîner des modèles NLP (type GPT-3 ou GPT-J) de plus de 20 milliards de paramètres sur une seule puce.
Alors, oui, c’est sûr, 20 milliards de paramètres, ça peut faire sourire les experts IA du moment. OpenAI et d’autres centres de recherches utilisent en effet les ressources quasi illimitées de clouds pour entraîner des modèles de réseaux de neurones de centaines de milliards de paramètres. Ainsi, OpenAI s’appuie sur un HPC assemblé pour eux dans Azure pour entraîner son IA « GPT-3 » avec ses 175 milliards de paramètres.
Mais Cerebras se contente d’une seule puce pour monter ses réseaux de 20 milliards de paramètres et ça fait toute la différence.
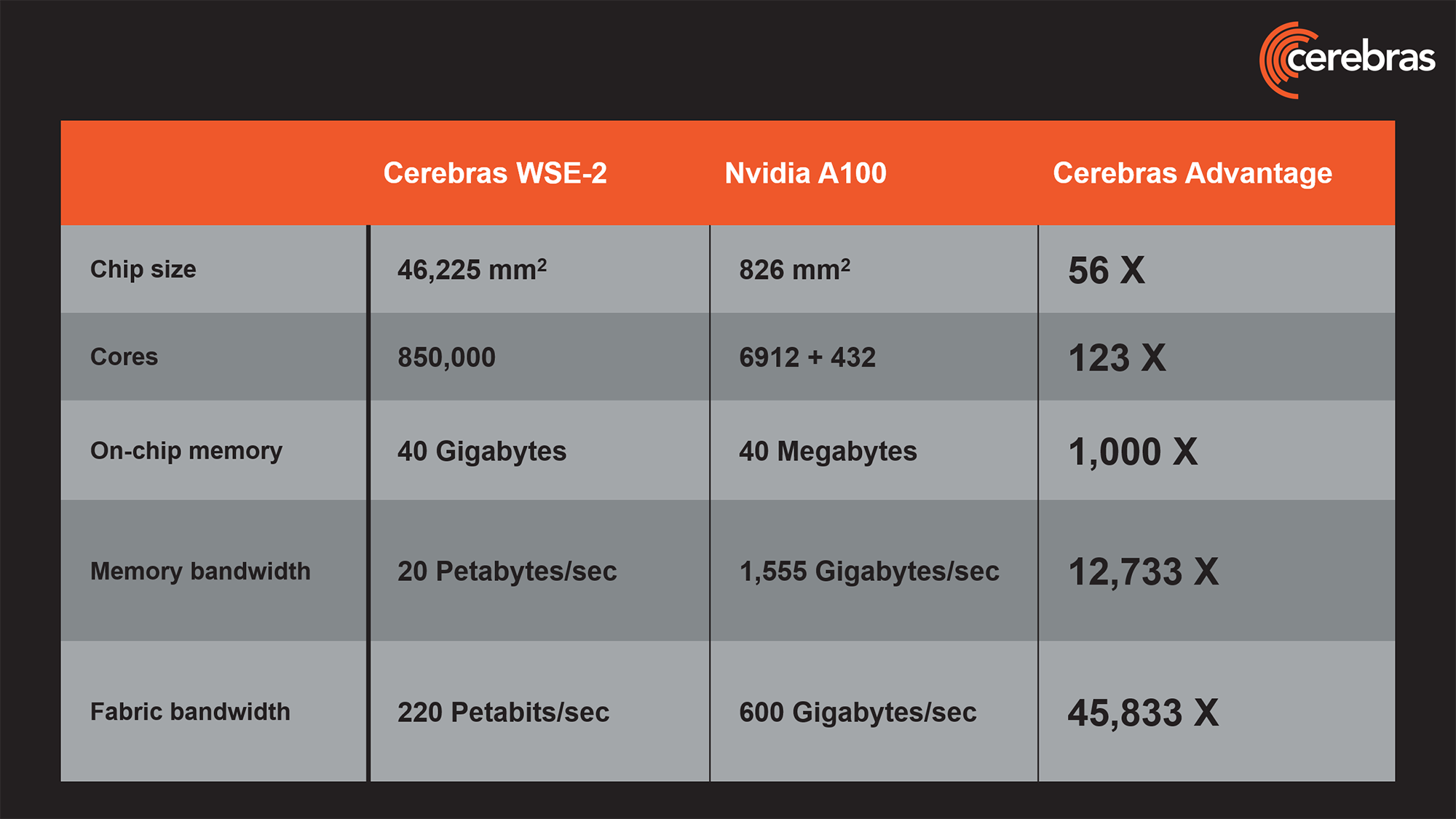
 Il est vrai que leur puce « IA », la Wafer-Scale Engine WSE-2, est plutôt monstrueuse : elle est 56 fois plus grosse qu’un GPU A100 de NVidia (un GPU calibré pour l’IA que l’on retrouve dans bien des HPC modernes) et embarque 850 000 cœurs de calcul Tensor Core (soit 123 fois plus que le A100 !).
Il est vrai que leur puce « IA », la Wafer-Scale Engine WSE-2, est plutôt monstrueuse : elle est 56 fois plus grosse qu’un GPU A100 de NVidia (un GPU calibré pour l’IA que l’on retrouve dans bien des HPC modernes) et embarque 850 000 cœurs de calcul Tensor Core (soit 123 fois plus que le A100 !).
La puce héberge également 40 Go de mémoire ultra rapide.
Un système CS2 – qui combine un processeur WSE2 et un système de stockage permanent nommé MemoryX – évite toute la complexité des architectures GPU hautement parallélisées jusqu’ici utilisées pour l’entraînement des réseaux de neurones de plusieurs milliards de paramètres. Et ses performances sont telles, que ce système produit aussi un résultat plus rapide. « Exécutés sur un seul CS-2, les modèles 20B GPT sont configurés en quelques minutes et les utilisateurs peuvent passer rapidement d’un modèle à l’autre en quelques clics. Avec des clusters de GPU, cela nécessite des mois de travail d’ingénierie » expliquent les ingénieurs de Cerebras dans un long billet de blog plutôt technique.
 « Le résultat est que non seulement les plus grands modèles NLP peuvent être exécutés sur un seul système, mais qu’ils peuvent être configurés rapidement et facilement débogués sans se soucier de parallélisme hybride et complexe, ajoutent les responsables. L’exécution d’un modèle à 20 milliards de paramètres est exactement la même que celle d’un modèle à 1 milliard de paramètres, il suffit de changer quelques chiffres dans un fichier de configuration. Et c’est tout ! Cela n’est pas possible sur les GPU, même avec des frameworks distribués sophistiqués, en raison des défis fondamentaux que représente la distribution du travail sur une multitude de systèmes ».
« Le résultat est que non seulement les plus grands modèles NLP peuvent être exécutés sur un seul système, mais qu’ils peuvent être configurés rapidement et facilement débogués sans se soucier de parallélisme hybride et complexe, ajoutent les responsables. L’exécution d’un modèle à 20 milliards de paramètres est exactement la même que celle d’un modèle à 1 milliard de paramètres, il suffit de changer quelques chiffres dans un fichier de configuration. Et c’est tout ! Cela n’est pas possible sur les GPU, même avec des frameworks distribués sophistiqués, en raison des défis fondamentaux que représente la distribution du travail sur une multitude de systèmes ».
Bref, vous l’aurez compris, Cerebras est un nom à retenir. Cette jeune pousse n’a pas froid aux yeux et n’a pas peur d’imaginer des processeurs totalement dingues et surdimensionnés. Ces derniers sont probablement hors de prix. Mais la startup propose désormais ses systèmes CS2 accessibles dans le cloud au travers de son offre « Cerebras Cloud @ Cirrascale ». En attendant une adoption chez les grands hyperscalers ?
À lire également :
La startup Cerebras présente le plus grand processeur jamais conçu
Project Volterra : Microsoft pousse simultanément ARM et NPU auprès des Devs
Après les CPU, les GPU, les NPU, les TPU… Intel invente les IPU !
Tesla inaugure son nouveau HPC pour entraîner son IA de conduite autonome
GPT-3, l’étonnante intelligence artificielle d’OpenAI qui écrit aussi bien que les humains…
Microsoft Singularity : une IA à l’échelle planétaire
Le Top100 des startups en intelligence artificielle

 puis
puis