
Apprendre à apprendre, tel est schématiquement le champ de ce que l’on appelle l’apprentissage automatique (machine learning). Des gros progrès vont ainsi permettre aux ordinateurs de sortir de leur cécité.
L’apprentissage automatique est l’un des champs d’étude de l’intelligence artificielle, est la discipline scientifique concernée par le développement, l’analyse et l’implémentation de méthodes automatisables qui permettent à une machine (au sens large) d’évoluer grâce à un processus d’apprentissage, et ainsi de remplir des tâches qu’il est difficile ou impossible de remplir par des moyens algorithmiques plus classiques (source Wikipedia).
Avec comme objectif de doter les ordinateurs de systèmes de perception de leur environnement : vision, reconnaissance d’objets ; moteurs de recherche ; aide aux diagnostics ; interfaces cerveau-machine ; détection de fraudes à la carte de crédit, analyse financière, dont analyse du marché boursier… Par rapport aux années 80/90 où l’on attendait beaucoup de l’intelligence artificielle et des systèmes experts et dont les résultats furent plutôt décevants, les technologies ont changé radicalement les approches des chercheurs dans de nombreux domaines avec des résultats aujourd’hui tout à fait spectaculaires. Deep Blue et son proche cousin Deeper Blue n’ont pas tant battu Gary Kasparov grâce à une meilleure stratégie mais plutôt à la capacité de compiler des millions de parties et ainsi de jouer le coup le mieux adapter en fonction des circonstances. Comme l’indique Feng-Hsiung Hsu, responsable de l’équipe qui a conçu Deep Blue d’IBM, dans un article de la revue Spectrum de l’IEEE, c’est plus la force brute de l’ordinateur a permis à l’ordinateur de battre l’homme que tout autre considération (Brute-force computation has eclipsed humans in chess, and it could soon do the same in this ancient Asian game). IBM a continué dans la même approche en utilisant capacités et performances des ordinateurs pour développer son système Watson qui a ensuite permis de battre les champions du jeu Jeopardy.
De même, les systèmes de traduction automatique (comme ceux de Google Translation) ont fait de grand progrès non pas par qu’ils connaissent mieux la grammaire, la sémantique, les subtilités des langues mais parce qu’ils sont capables d’analyser des volumes considérables de textes et ainsi de trouver la traduction la mieux adaptée en fonction du contexte.
De nombreux domaines vont être totalement révolutionnés grâce à une telle approche. La startup californienne Second Spectrum a développé un système de prévision du championnat de la NBA permettant, comme l’indique son CEO Rajiv Maneswaran, « de faire la différence entre un mauvais jouer qui réalise une action exceptionnelle et un bon joueur qui rate un coup ».
La vision est un domaine dans lequel de très gros progrès sont attendus tant les capacités des ordinateurs sont, encore à ce jour, limitées. En 2007, Fei-Fei Li, responsable du programme Computer vision and machine learning du laboratoire d’IA de l’université de Stanford, a abandonné l’idée de programmer des ordinateurs afin qu’ils puissent reconnaître des objets et adopté une nouvelle approche consistant à compiler des millions d’images (triées, nettoyées, standardisées, classées…) auxquels un enfant de trois ans a été exposé depuis sa naissance. Aujourd’hui, elle a développé un système capable d’identifier les éléments visuels d’une image avec un assez haut niveau de précision.
Dans un monde où l’image joue un rôle de plus en plus important, les machines ont fait de réels progrès. Témoin les voitures autonomes. « Et pourtant, les machines ont encore beaucoup de difficultés à comprendre et analyser de simples images, explique Fei-Fei li dans une conférence Ted (voir ci-dessous). Il y a encore beaucoup de chemin à parcourir pour atteindre le stade de ce qu’elle appelle la vision intelligente et qui permet de comprendre ce que l’on voit. Evidemment, il a fallu quelque 500 millions d’années à l’homme pour développer une telle capacité ».
« Nous restons aveugles car nos machines les plus performantes sont toujours aveugles, poursuit-elle. Et pourtant, on n’apprend pas à un enfant à voir.
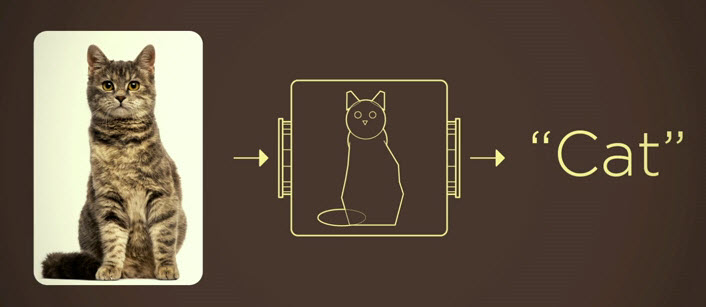
La première étape dans ce processus est de rendre les ordinateurs capables d’identifier des objets. Prenons l’exemple du chat qui peut se définir et donc se modéliser de manière relativement simple à partir de paramètres simples : couleurs, formes… Mais ce processus laisse parfois quelques surprises comme le montrent les photos ci-dessous et qui sont de nature à désorienter les ordinateurs. Sur ce simple exemple du chat, la réalité peut présenter d’innombrables variations qui rendent la modélisation plus complexe. D’où l’idée de changer complètement d’approche. Au lieu d’améliorer les algorithmes de reconnaissance de forme, cette nouvelle approche consiste à « entraîner » les ordinateurs et à les exposer à des millions d’images. C’est l’origine du projet Imagenet lancé en 2007 qui réunit aujourd’hui dans une base de données de 15 millions d’images classées dans 22 000 catégories à partir de la collecte de plus d’un milliard récupérées via Internet et une approche de type crowdsourcing. Par exemple, Imagenet réunit plus de 60 000 images de chats. Cette base de données a permis de « nourrir » des algorithmes spécialisés baptisés Convolutional neural network. Le système permet ainsi de reconnaître divers éléments d’une image (voir les photos ci-dessous).


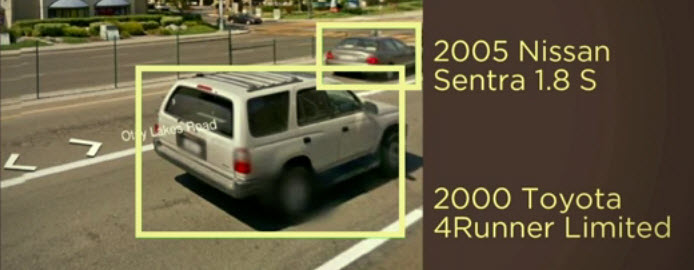
 Lorsque l’image est ambiguë, le système fait preuve d’une certaine prudence et donne une réponse appropriée. En revanche, dans certaines situations, il fait preuve d’une précision plus grande que celle d’un humain en donnant des caractéristiques très spécifiques comme la marque et l’année d’un véhicule automobile.
Lorsque l’image est ambiguë, le système fait preuve d’une certaine prudence et donne une réponse appropriée. En revanche, dans certaines situations, il fait preuve d’une précision plus grande que celle d’un humain en donnant des caractéristiques très spécifiques comme la marque et l’année d’un véhicule automobile.
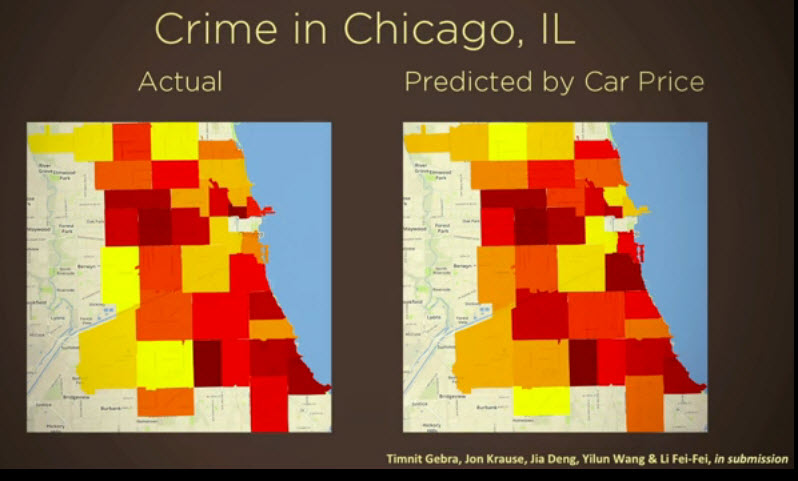
Ces études associées avec des bases de données ont permis par exemple de croiser des millions d’images prises par Google Street et d’obtenir des résultats spectaculaires : corrélation entre prix des voitures et revenu des ménages, taux de criminalité ou vote.
Mais il reste beaucoup à faire, poursuit Fei-Fei Li. Pour l’heure, notre machine est dotée d’une vision équivalente à celle d’un enfant de trois ans. Une nouvelle étape sera de permettre à l’ordinateur de comprendre des images et de générer des phrases en langage naturel décrivant la situation. Comme par exemple : un chat assis sur un lit. Des premiers résultats ont déjà été obtenus mais de grands progrès restent à accomplir, le système fait toujours quelques erreurs (voir ci-dessous). « Le défi consiste à simuler les capacités d’un adolescent de 13 ans » conclut Fei-Fei Li.



 puis
puis