
Lorsque l’on parle de sécurisation du code source, on pense souvent aux tests statiques (SAST) ou à l’analyse de la composition du logiciel (SCA). Alors comment expliquer que des acteurs majeurs du monde DevOps revendiquent l’émergence d’un nouveau segment appelé “détection de secrets” ?
Les développeurs manipulent des quantités croissantes de secrets tels que des clés d’API pour interconnecter des infrastructures cloud, des plateformes SaaS, des bases de données et des microservices.
Comme ces informations d’identification sont faites pour être utilisées de manière programmatique, elles se retrouvent trop souvent dans le code source, ce qui constitue une menace majeure.
Dans cet article, nous examinerons les raisons fondamentales pour lesquelles la façon de développer des logiciels a changé si radicalement que les secrets dans le code source sont devenus un problème majeur, et pourquoi les solutions existantes telles que les programmes de formation des développeurs, les revues de code et les solutions de gestion des secrets ne sont pas suffisantes.
La façon dont les applications sont développées a créé un nouveau défi.
Les applications ne sont plus des monolithes autonomes, elles reposent désormais sur des milliers de blocs indépendants : infrastructure cloud, bases de données, composants SaaS tels que Stripe, Slack, HubSpot, pour n’en citer que quelques-uns. Il s’agit d’un changement important dans le développement de logiciels. Les secrets sont la colle qui relie ces différents blocs qui composent une application en établissant une connexion sécurisée entre eux, leur permettant de transmettre des informations et des données.
L’utilisation de cette méthode d’architecture distribuée présente de nombreux avantages, notamment la possibilité de mettre à jour les services de manière indépendante, de faire évoluer les services rapidement et de décharger le travail de développement vers des services dédiés tels que les fournisseurs de SaaS. Il y a toutefois un inconvénient, car il faut maintenant gérer tous les secrets qui relient ces différents éléments, ce qui peut représenter des centaines, voire des milliers de secrets.
Comme ces secrets sont conçus pour être utilisés par programme, ils finissent souvent par être codés en dur dans le code source. Cela peut se faire en les incluant dans le code source de l’application, dans les fichiers de configuration, dans les fichiers d’environnement, ou par tout autre moyen. Le problème est que le code source est très diffusé. Le code est copié et transféré partout et git est conçu de manière à permettre, voire promouvoir, la libre distribution du code. Les projets peuvent être clonés sur plusieurs machines, forkés vers de nouveaux projets, distribués à des clients, rendus publics, etc. Chaque fois qu’il est dupliqué sur git, l’historique complet de ce projet est également dupliqué.
Le pire endroit où les secrets peuvent se retrouver est les dépôts git publics, pourtant cela se produit avec une régularité alarmante. Le rapport 2022 State of Secrets Sprawl montre que plus de 6 millions de secrets ont été détectés dans des dépôts publics en 2021, une augmentation de 50% par rapport à 2020. Ces chiffres n’incluent bien sûr pas le nombre énorme de secrets à l’intérieur de dépôts privés.
Pourquoi les solutions existantes ne permettent pas de résoudre ce problème ?
La façon dont les applications sont développées a évolué, tout comme la façon dont travaillent les développeurs et la manière dont ils protègent le code. Toutes ces mesures sont excellentes pour assurer la sécurité du code, mais elles ne permettent pas d’empêcher efficacement la prolifération des secrets.
Les fuites de secrets constituent un défi unique en matière de sécurité, différent de toutes les autres vulnérabilités, car la menace d’une fuite de secret existe pendant toute la durée de vie d’un projet.
Si nous examinons d’autres vulnérabilités courantes telles que XSS, l’injection de code, les vulnérabilités dans les dépendances… Le point commun de toutes ces vulnérabilités est qu’elles ne présentent un risque que dans la version actuelle ou de production d’une application. Si une entreprise a une vulnérabilité XSS dans son code, une fois que celui-ci a été mis à jour et qu’une nouvelle version a été publiée, cette vulnérabilité n’est plus un problème. Si l’organisation a une dépendance vulnérable, une fois qu’elle a été corrigée et mise à jour, il n’y a plus de risque. Cependant, divulguer un secret dans git, même s’il est supprimé, reste un risque jusqu’à ce qu’il soit révoqué. En effet, les outils utilisés conservent des enregistrements de toutes les modifications et il suffit à quelqu’un d’aller fouiller dans notre historique pour découvrir la vulnérabilité. Les revues de code en sont un bon exemple.
Détecter les secrets lors des revues de code (ou pas)
Un grand avantage de git est de pouvoir voir rapidement et clairement les modifications apportées et de comparer les états précédents et proposés du code. Il est donc courant de croire que si des secrets sont divulgués dans le code source, ils seront bien sûr détectés lors d’une revue du code ou dans une demande de modification.
Les revues de code sont un excellent moyen de détecter les défauts de logique et de maintenir la qualité du code en appliquant de bonnes pratiques de code. Mais elles ne constituent pas un moyen fiable de détecter les fuites de secrets dans le code source. En effet, les revues ne s’intéressent généralement qu’à la différence nette entre l’état actuel et l’état proposé. Les revues de code ne prennent pas en compte l’historique complet d’une branche de développement. Ceci est problématique car les branches sont souvent nettoyées avant une revue, le code temporaire utilisé pour les tests est supprimé, les fichiers journaux et autres documents inutiles sont supprimés afin qu’ils ne se retrouvent pas dans la branche principale. Le problème est qu’ils sont dans l’historique, à moins que le réviseur ne parcoure l’historique complet de la branche, ce qui peut représenter un travail considérable, tous les secrets précédemment présents resteront dans l’historique.
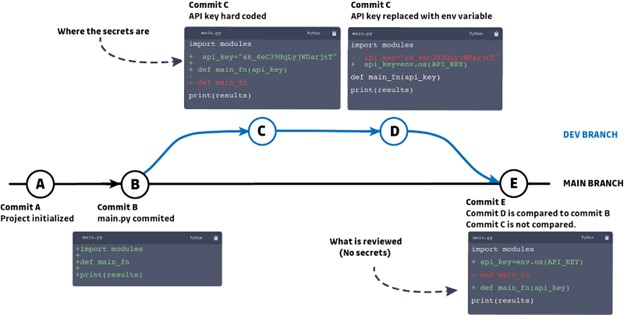
Fig 1 : une version simplifiée d’un arbre git qui démontre cette problématique.
Une nouvelle branche de développement est créée et le développeur, désireux d’agir rapidement, code en dur des secrets dans le code source (commit C). Après avoir finalisé les modifications et obtenu que la fonctionnalité fonctionne comme prévu, il nettoie son code, en supprimant les secrets codés en dur et en les remplaçant par des variables d’environnement.
Solutions de gestion des secrets
Les systèmes de gestion des secrets participent la lutte contre la prolifération des secrets, mais quelle que soit la puissance des outils et des politiques en place, s’il y a une personne impliquée, et c’est toujours le cas, il y a un risque de fuite de secrets.
Si une personne veut aller d’un point A à un point B, il est évident qu’elle choisira le chemin de moindre résistance pour y arriver. Si nous pouvons choisir un chemin et éviter les obstacles inutiles, nous l’emprunterons certainement.
La même logique peut être appliquée à la gestion des secrets. Le fait de chiffrer les secrets et de les garder étroitement protégés avec un contrôle d’accès rend leur accès et leur distribution beaucoup plus difficiles pour les développeurs. Il est donc tentant de choisir la voie de la moindre résistance, qui peut consister à les coder en dur, à les stocker dans des endroits faciles d’accès, à les partager par des canaux non sécurisés comme les systèmes de messagerie, à les enregistrer dans des fichiers de configuration ou même à les stocker dans des wikis internes.
Introduction à la détection de secrets
Des solutions de détection de secrets ont vu le jour. L’accélération rapide de la prolifération des secrets et son utilisation dans de nombreux breachs importants ont conduit des acteurs majeurs tels que GitHub et GitLab à introduire la détection de secrets dans leurs offres de sécurité en tant que fonctionnalité indépendante.
La détection de secrets est cependant difficile à mettre en place. En effet, elle est probabiliste, c’est-à-dire qu’il n’est pas toujours possible de déterminer ce qui est un vrai secret (ou un vrai positif).
Nous devons prendre en compte la probabilité qu’un secret soit un vrai positif sur la base de multiples indicateurs différents et de signaux faibles. Certains secrets ont des modèles fixes qui peuvent être identifiés, mais la plupart n’en ont pas. Ils peuvent également avoir différents jeux de caractères, différentes longueurs et apparaître dans de nombreux contextes différents. Tous ces éléments font qu’il est extrêmement difficile de détecter des secrets avec précision sans signaler les faux positifs.
Un autre aspect important de la détection des secrets est le choix d’une solution capable de détecter des secrets dans un périmètre plus large. Pas seulement dans les référentiels contrôlés par l’entreprise, mais aussi dans les référentiels personnels des employés. En fait, seulement 15 % des fuites de secrets se produisent dans les référentiels des entreprises, les 85 % restants se produisent dans les référentiels personnels des développeurs. De nombreux incidents de sécurité très médiatisés se sont produits à la suite de fuites et de découvertes de secrets dans les référentiels des employés, notamment chez Uber et, plus récemment, chez Solarwinds ou encore Codeco.
La façon dont les applications sont développées a radicalement changé pour inclure un système distribué de blocs reliés entre eux par des secrets. Ces secrets sont souvent codés en dur dans le code source, car ils sont conçus pour être utilisés de manière programmatique, ce qui peut entraîner leur fuite. La fuite de secrets est une menace unique pour les organisations car, contrairement aux autres vulnérabilités, une fois qu’un secret a été divulgué, il reste une menace pendant toute sa durée de vie. Après tout, il reste accessible dans l’historique du projet. Pour cette raison et parce que le logiciel comportera toujours un élément humain sujet à des erreurs, les outils actuels de sécurité des applications ne sont pas adéquats pour nous protéger de cette nouvelle menace. Cette situation a donné naissance à un nouveau segment de la sécurité applicative appelée détection automatique de secrets. Bien que simple dans son concept, la détection des secrets dans le code source est intrinsèquement difficile en raison de la nature probabiliste des secrets. De plus, les secrets peuvent se diffuser dans des actifs sur lesquels les organisations n’ont aucun contrôle, comme les dépôts git des employés. Pour ces raisons, les organisations doivent s’assurer que la solution qu’elles choisissent pour lutter contre ce problème est non seulement dotée d’un système de détection adéquat, mais qu’elle couvre également les actifs internes et externes à l’organisation.
___________________
Par Mackenzie Jackson, developer advocate GitGuardian

 puis
puis