
La Business Intelligence (BI) permet de valoriser les données issues des Systèmes d’Information (SI) opérationnels. Le Big Data promet d’exploiter des données, internes ou externes, massives et multi-structurées afin d’enrichir les insights permettant une prise de décision plus pertinente encore. L’automatisation du traitement des données est de plus en plus forte et performante. Pourtant, trop d’équipes métiers passent encore un temps considérable à collecter manuellement des données clefs, conservées et exploitées hors du SI d’Entreprise : les « Small Data ». Ce sont généralement des données à faible volumétrie mais de structure complexe et fortement évolutive, caractéristiques qui rendent pratiquement impossible leur intégration par des approches classiques de type IHM[1] et/ou ETL[2]. Les « Small Data » sont donc souvent ignorées par l’informatique d’entreprise. Pourtant, leur collecte est un véritable enjeu de productivité, tandis que leur intégration aux environnements décisionnels est un facteur clef du bon pilotage de la performance et de la valorisation des investissements de BI traditionnelle ou de Big Data.
Les small data, chaînon manquant du pilotage de la performance
Imaginez le cas d’école suivant : un chargé d’étude doit produire un tableau de bord avec une ligne par usine, une colonne pour la production réelle et une autre pour le prévisionnel. Normalement, cela donne ce tableau très simple :
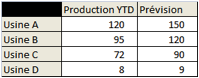
Malheureusement, l’usine C est d’acquisition récente et n’a pas encore migré sur l’ERP[3] d’entreprise. Quant à l’usine D, elle est trop petite pour qu’il soit envisageable de jamais la migrer sur l’ERP : en conséquence, les données de production de ces deux usines ne sont pas disponibles dans le Datawarehouse d’entreprise. Par ailleurs, les données prévisionnelles ne sont pas non plus disponibles dans le SI d’entreprise et le Datawarehouse.
Finalement, l’environnement décisionnel ne contient que les données pour alimenter les deux cases en haut à gauche. Soit seulement un quart du tableau :

Le reste devra être alimenté à partir de données non présentes dans le SI : déclaratives, elles seront le plus souvent collectées, stockées et analysées dans Excel, et ce directement par les équipes métiers.
Le traitement des small data, une informatique de l’ombre
Toutes les entreprises se trouvent confrontées à des situations similaires au cas ci-dessus. Pour ces données ignorées par l’informatique d’entreprise, la solution ad hoc adoptée par les métiers est généralement Excel : le tableur permet à la fois de construire des formulaires de collecte, de conserver les données recueillies, de les consolider et d’analyser les résultats. Excel est simple à mettre en œuvre et ne requiert pas de compétences particulières ; c’est le couteau suisse des équipes métiers.
Malheureusement, l’utilisation d’Excel dans ce contexte pose deux problèmes : d’une part, quand le nombre de contributeurs ou de données à collecter s’accroît, la mécanique Excel devient terriblement chronophage. L’utilisation de macros Visual Basic ou d’Access permet d’améliorer la productivité mais cela requiert des compétences plus techniques et s’avère à l’usage difficile à maintenir : combien de macros VB ou de bases Access deviennent tout simplement inexploitables un ou deux ans à peine après leur mise en place ?
D’autre part, les données collectées via Excel ne peuvent généralement pas être réintégrées dans l’environnement décisionnel. Pour les croiser avec les autres données, il faut donc extraire ces dernières du SI, et produire analyses et rapports directement sous Excel. Ainsi, non seulement l’utilisation d’Excel est doublement chronophage (pour la collecte et pour l’analyse) mais de plus, elle détourne les utilisateurs des outils de restitution et d’analyse déployés dans l’entreprise (le plus souvent à grands frais).
De nombreuses équipes métiers se retrouvent victimes de leur succès : ayant prouvé la valeur des données collectées via Excel, elles sont condamnées à les « produire » de façon récurrente, mobilisant de facto leurs collaborateurs sur des tâches mécaniques et peu valorisantes…
En parallèle, les investissements BI classiques sont sous-exploités : s’appuyant sur un modèle de données incomplet, ils ne peuvent pas répondre à l’ensemble des besoins de reporting et voient en conséquence les utilisateurs s’en détourner. Cela remet en question leur rentabilité.
Où en sont les entreprises dans la valorisation des small data ?
Face à ce problème, la réponse traditionnelle des directions informatiques consiste généralement à proposer le développement d’une IHM Web ad hoc. Mais cette approche se heurte à une difficulté majeure : elle ne permet pas de capitaliser sur l’existant Excel, qui pourtant représente finalement un investissement significatif et opérationnel ; il faut en effet « tout casser pour tout refaire ». Cela implique des coûts et délais importants qui ne peuvent être réduits qu’en arbitrant des fonctionnalités : les utilisateurs métiers rechignent alors à un transfert de technologie qui, tout en restant coûteux, implique des pertes de fonctionnalités. D’autant plus que l’évolutivité de telles solutions ne pourra jamais être aussi bonne qu’avec Excel, et qu’il existe un effet tunnel significatif sur ce type de projet.
Et pourtant, d’autres solutions existent. Ces solutions permettent d’atteindre plusieurs objectifs inenvisageables avec Excel (même complété de VB et d’Access) :
– Automatisation des processus de collecte pour éliminer toutes les tâches manuelles (préparation des formulaires à partir des référentiels existants, envoi, suivi des réponses, relance, consolidation…),
– Fiabilisation de la donnée par la mise en place de contrôles complexes à la saisie et/ou de piste d’audit,
– Intégration automatique des données collectées dans une base de données structurée interconnectable avec le reste du SI.
Au-delà de ces trois apports majeurs, le succès de ces technologies tient en plusieurs facteurs :
– Leur faible coût de mise en place, permis notamment par une adhérence technique minimale avec le reste du SI et par leur capacité à capitaliser sur l’existant Excel (qui constitue généralement le réceptacle d’une véritable expertise métier),
– Leur faible coût d’exploitation, basé à la fois sur une tarification légère et sur une maintenance simple,
– Leur simplicité de mise en œuvre qui permet aux équipes métiers de garder la main sur les processus de collecte et leur évolution,
– Leur bonne évolutivité et leur stabilité sur le long terme.
Pour ces technologies, l’aspect coût est évidemment primordial : le plus souvent, les gains financiers escomptés suite à l’industrialisation du processus sont trop faibles en regard du coût d’une solution traditionnelle du type IHM Web. La simplicité de mise en œuvre et l’évolutivité sont aussi des points importants pour les équipes métiers, qui s’inquiètent généralement de charges projets importantes et d’une perte de contrôle de leurs processus clefs.
Quelles solutions pour le traitement des small data ?
Commençons d’abord par noter que la plate-forme BI de Microsoft permet d’intégrer Excel au sein d’une architecture BI complète largement conçue autour du tableur mais intégrant l’ensemble des fonctionnalités de data management : ETL, DBMS, gestion de référentiels. Elle constitue donc une solution BI de choix pour les organisations « Excel intensives ».
Continuons en évoquant les verticaux métiers « de niche ». Il s’agit de solutions dédiées à un métier spécifique. Il faut tout de même une certaine masse critique et une relative homogénéité des processus pour permettre l’émergence d’un progiciel sur un métier donné. C’est pourquoi ces « verticaux métiers » concernent principalement les deux directions présentes dans toutes les entreprises : Direction des Ressources Humaines (GPEC, bilan social…) et Direction des Affaires Financières (gestion de trésorerie, suivi budgétaire…). On peut citer à titre d’exemple (non exhaustif) BPC (SAP), IBM TM1, SAS Financial Management, Tagetik ou Anaplan pour la planification budgétaire, IBM Varicent pour la gestion de la rémunération variable ou encore Enablon pour la Responsabilité Sociétale d’Entreprise.
Enfin, pour les besoins plus spécifiques, quand il n’existe pas de vertical métier clef en main, des solutions généralistes permettent d’automatiser les processus à moindre coût. Ces solutions du marché ont en commun les caractéristiques suivantes :
- Pas de modèle de données précontraint : pour chaque cas métier, le modèle accueillant les données collectées est défini librement en fonction des besoins spécifiques. Cela permet une grande souplesse de mise en œuvre et facilite le partage avec le reste du SI.
- Possibilité de collecter non seulement des données au sens traditionnel du terme, mais également des métadonnées, des commentaires, des pièces jointes de toute sorte.
- Traçabilité des contributions et workflow de collecte / validation.
- Grande simplicité du déploiement des formulaires de collecte car ils ne requièrent pas l’installation d’un client lourd sur les postes des contributeurs.
- Importante autonomie des équipes métiers dans la gestion de la solution, y compris dans la mise à jour des référentiels.
A titre d’illustration, on peut citer deux solutions ayant chacune leurs points forts spécifiques :
Referential Data Administration (ou RDA) de Vision BI[4] : cette solution permet à un administrateur fonctionnel de créer en quelques clics une interface web de saisie de données de référentiel. Il s’agit d’un outil assimilable à du MDM[5] très simple. Il permet de mettre en place des contrôles de cohérence simples. Les points clefs de cette solution sont :
– L’autonomie totale des équipes fonctionnelles pour la création de nouveaux formulaires ;
– L’immédiateté de la mise en œuvre et du déploiement d’un nouveau formulaire ;
– Le fait de pouvoir adresser simultanément plusieurs sources de données à partir d’un même portail ; cela permet de positionner la donnée collectée directement au cœur du SI.
Gathering Tools (ou GT) de Calame Software : cette solution permet de créer des formulaires de saisie sécurisés qui reproduisent parfaitement l’apparence et les fonctionnalités des classeurs Excel les plus complexes. Les points clefs de la solution sont :
– Les formulaires GT sont créés directement à partir des classeurs Excel ; cela permet de capitaliser sur l’existant, et notamment sur les règles métiers et l’ergonomie existante. Cela permet des cycles projets très courts et une conduite du changement simplissime pour le métier ;
– Les formulaires GT offrent des fonctions de contrôles de saisies et de cohérence bien plus avancées qu’Excel : cela contribue très significativement à l’amélioration de la qualité des données collectées ;
– Le système de workflow qui permet d’automatiser la gestion des campagnes de collecte (pré-remplissage des formulaires avec personnalisation par destinataire, suivi des réponses, envoi de relance, intégration des réponses) ; les campagnes impliquant plusieurs centaines de contributeurs se gèrent en quelques clics.
– La possibilité de travailler en mode connecté ou déconnecté.
Les deux solutions ont en commun d’intégrer automatiquement les données collectées dans une base de données structurées, directement utilisable pour le reporting : ainsi, ces données sont immédiatement et automatiquement consommables par les autres applications du SI, notamment les outils BI. De ce fait, ces outils sont plébiscités à la fois par les métiers et par l’IT.
En termes de méthodologie, les solutions présentées sont parfaitement accessibles à des utilisateurs non informaticiens, ce qui permet aux équipes métiers de garder le contrôle de leurs processus. Pour autant, ce type de projet ne se doit pas se faire « contre » l’informatique, mais bien en collaboration étroite avec celle-ci pour assurer la valorisation des données collectées dans l’ensemble de l’environnement décisionnel de l’entreprise. Cette coordination, ainsi que le choix du bon outil et la montée en compétence des équipes peuvent requérir un accompagnement initial.
En conclusion, à l’heure de l’émergence du Big Data, il ne faut pas perdre de vue qu’il existe encore des potentiels très importants de gain de productivité, de qualité et de performance dans l’optimisation des processus de collecte des « Small Data ». L’émergence de nouveaux outils permet désormais de réaliser ces gains de productivité avec un ROI très avantageux tout en valorisant les investissements déjà faits par les équipes métiers. Ce type de projet constitue à la fois un vrai levier d’amélioration de la performance de l’entreprise et un vecteur de valorisation des profils métiers qui peuvent se recentrer sur des missions métiers à plus forte valeur ajoutée.
[1] IHM (interface homme machine) : application permettant à un utilisateur métier de saisir des données dans un système d’information.
[2] ETL (Extract, Transform, Load) : outil informatique permettant de transformer des données pour les transférer d’un système d’information à un autre.
[3] ERP : Enterprise Ressource Planning
[4] Vision BI est une filiale du Groupe Keyrus.
[5] Le MDM (pour Master Data Management) est un domaine de l’informatique qui s’intéresse à la gestion synchronisée des référentiels clefs de l’entreprise (référentiel client, tiers, produits, centres de structure, etc…). Le MDM s’appuie généralement sur des progiciels dédiés qui permettent de synchroniser les différentes sources et utilisations des référentiels.
__________
Cet article a été rédigé par Fakhreddine Amara, Directeur Conseil et Intégration de Keyrus et Sébastien Preau, Manager Conseil BI de Keyrus

 puis
puis