
Alors que Google est critiqué pour avoir quelque peu falsifié ses vidéos marketing autour de son nouveau modèle fondation Gemini Ultra, Microsoft Research montre que GPT-4 n’est pas démodé, loin de là.
En matière d’IA générative aujourd’hui, le prompt reste la clé pour déverrouiller la puissance réelle des modèles génératifs.
La semaine dernière, Google dévoilait ses nouveaux modèles fondation « Gemini » et affirmait, preuves à l’appui, que son modèle « Gemini Ultra » surpassait son concurrent « GPT-4 » sur la plupart des tests académiques MMLU conçus pour évaluer les IA. Certains observateurs avaient toutefois relevé que l’éditeur n’avait pas forcément appliqué les mêmes Prompts pour interroger son IA et celles concurrentes. Dit autrement, l’équipe de Google aurait optimisé les prompts pour sa propre IA mais pas pour les autres.
L’impact des prompts sur GPT-4 et Gemini Ultra
Une nouvelle étude Microsoft Research démontre une nouvelle fois non seulement la fragilité de telles comparaisons et benchmarks mais surtout l‘importance vitale du prompt et donc de la formulation des requêtes.
Le centre de recherche de l’éditeur américain avait développé il y a quelques mois un outil connu sous le nom de Medprompt, utilisant différentes techniques avancées de génération d’invites permettant d’améliorer considérablement les performances de GPT-4 et d’obtenir des résultats plus pertinents sur des questions médicales.
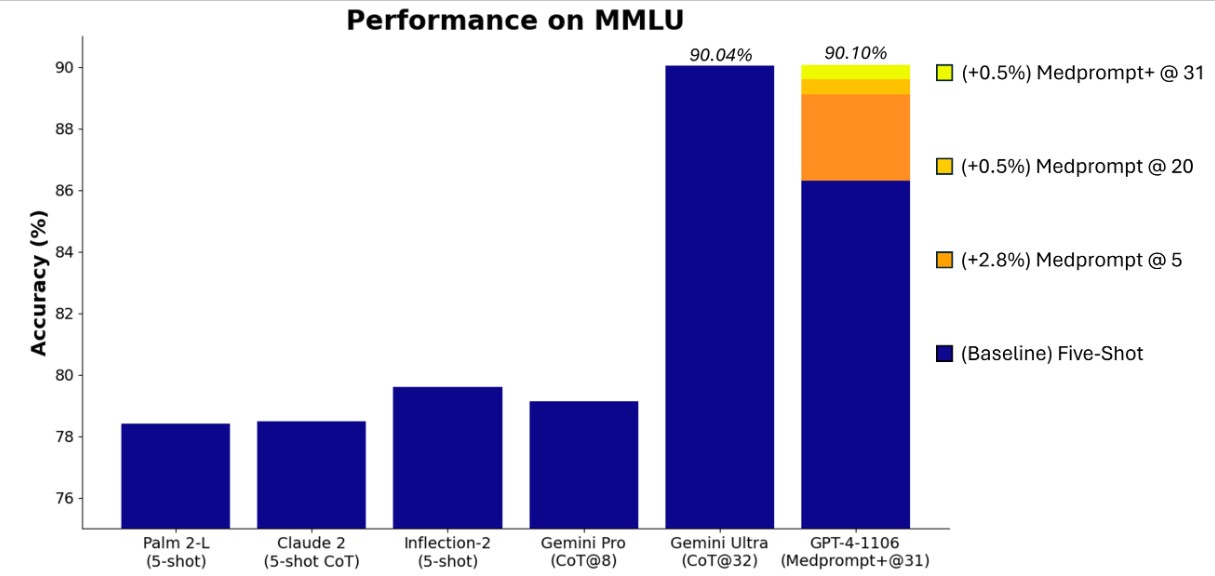
Microsoft a maintenant appliqué ces techniques d’invites (ou prompts) à des domaines plus généraux. Et selon les chercheurs, le modèle GPT-4 d’OpenAI utilisé avec cette version modifiée et plus universelle de Medprompt, dénommée Medprompt+, atteint le score le plus élevé jamais obtenu sur l’ensemble du benchmark MMLU justement choisi par Google pour évaluer « la suprématie » de Gemini.
L’expérience des chercheurs montre que non seulement nous n’avons pas atteint le plein potentiel d’un modèle comme GPT-4 (qui, l’air de rien, commence à dater puisqu’introduit en mars 2023) mais que, interrogé avec ces techniques d’optimisation des invites, GPT-4 affiche des scores supérieurs à Gemini Ultra (en ce basant sur les résultats publiés par Google, le modèle n’étant pas encore disponible). Et atteint ainsi un score MMLU supérieur. La différence est certes mineure (90,10% contre 90,04%).
Pour ceux qui veulent en apprendre plus sur les techniques de prompts développées par Microsoft Research, celles-ci sont publiées en open-source à cette URL :
GitHub – microsoft/promptbase: All things prompt engineering
Reste que tous ces tests restent très théoriques et que l’expérience en pratique peut finalement se révéler très différente. En outre, la force de Gemini Ultra semble bien davantage résider dans les cas d’usage multimodaux et non dans les discussions textuelles. On en sera plus dans quelques mois, lorsque Google libèrera réellement son modèle Ultra.
Phi-2 : un micro-modèle plus puissant que « Gemini Nano »
Dans le même temps, une autre équipe Microsoft Research a dévoilé un nouveau modèle IA « compact » destiné à une inférence locale sur PC ou même smartphones. Les « petits » modèles aussi appelés SLM, ont le vent en poupe. Ils peuvent en effet se montrer plus performants que des modèles plus gros s’ils sont entraînés de façon spécialisée avec des contenus de meilleure qualité. C’est toute l’approche d’une startup comme Mistral AI par exemple.
En annonçant « Gemini » la semaine dernière, Google avait introduit une version « Gemini Nano » destinée notamment à être déployée sur ses smartphones Pixel 8.
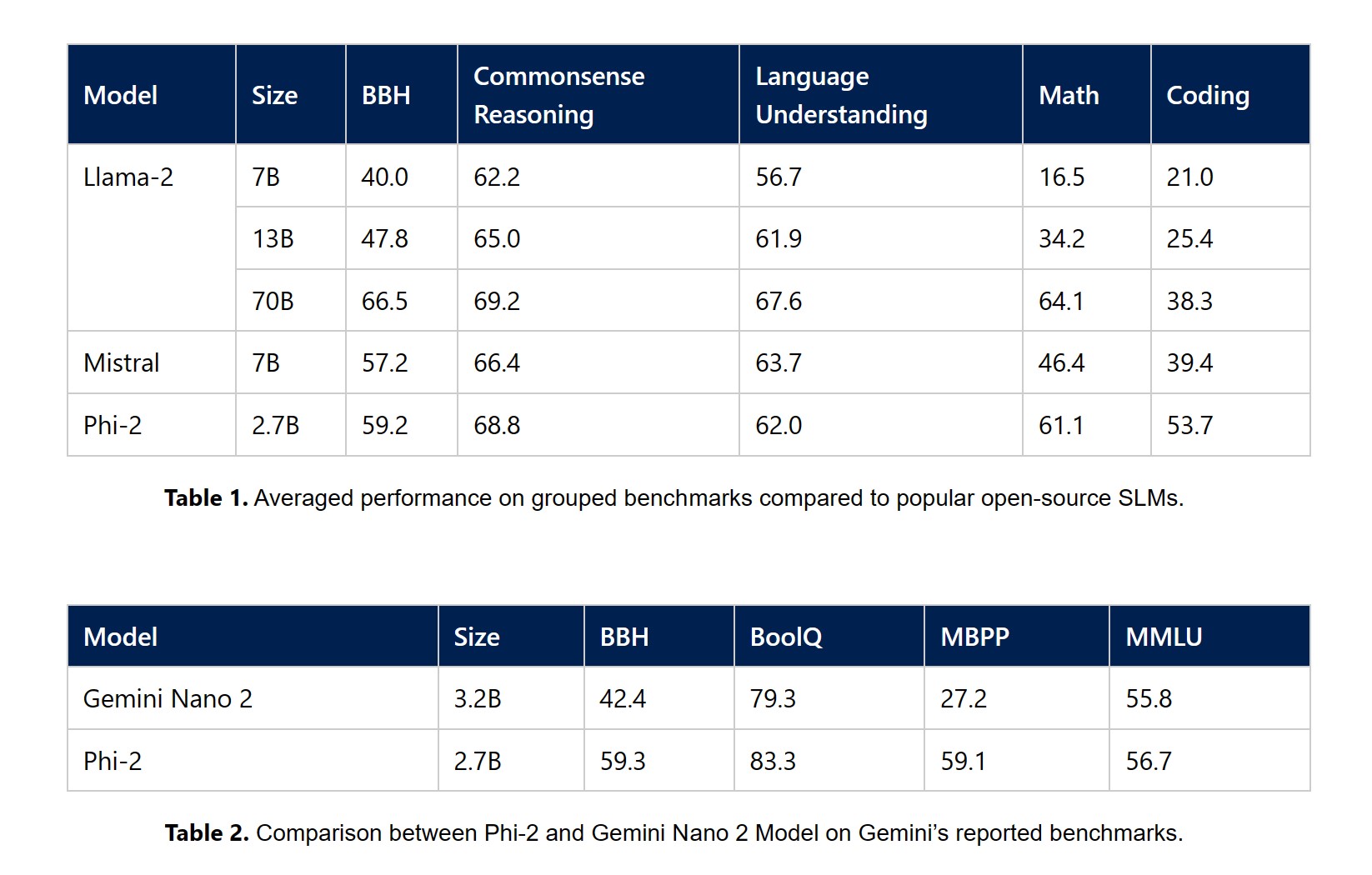
Cette semaine, Microsoft Research a dévoilé « Phi-2 », un modèle qui se veut plus efficient encore que Gemini Nano ou Mistral-7B.
Les LLM comme GPT-4 ou Gemini Ultra sont extrêmement consommateurs d’énergie et extrêmement coûteux en ressources et en GPUs. Les multiplier n’a pas de sens lorsque de petits modèles spécialisés peuvent faire le travail aussi bien tant que l’on reste dans le cas d’usage de leur spécialisation. La tendance est donc à la réduction de la taille des modèles IA et à leur spécialisation.
Doté de 2,7 milliards de paramètres « seulement », Phi-2 égalerait et parfois même surpasserait des modèles fondation 25 fois plus vastes. Selon Microsoft, Phi-3 présente des capacités exceptionnelles de raisonnement et de compréhension du langage, établissant une nouvelle norme de performance parmi les SLM de moins de 13 milliards de paramètres.
Fondamentalement, Phi-2 ne diffère pas vraiment des modèles GPT d’openAI. C’est un modèle « Transformer » avec un objectif de prédiction du mot suivant, entraîné sur 1 400 milliards de tokens provenant de différents ensembles textuels. Le processus d’entraînement – mené sur 96 GPU A100 pendant 14 jours – prétend surpasser les modèles open-source en termes de toxicité et de biais.
L’attention de Microsoft s’est notamment focalisée sur deux aspects qui font la différence :
* La qualité des données de formation : Phi-2 exploite des données de « qualité livre « , en se concentrant sur des ensembles de données synthétiques conçues pour transmettre un raisonnement de bon sens et des connaissances générales. Le corpus de formation est complété par des données web soigneusement sélectionnées, filtrées en fonction de leur valeur éducative et de la qualité de leur contenu.
* De nouvelles techniques de montée en charge développées par Microsoft Research à partir des travaux réalisés sur Phi-1 et Phi-1.5.
Autant d’informations qui doivent rappeler à tous que les grands modèles ne sont pas la solution à tous les cas d’usage, que les données d’entraînement a la principale clé de qualité des modèles et que l’année 2024 nous promet un flux ininterrompu d’innovations en matière d’IA.

 puis
puis